Zusammenfassung
Der aktuelle politische Moment in den USA ist kaum ohne Rückgriff auf das zu verstehen, was einmal als Technopolitik bezeichnet wurde. Politik mit und durch Technologie hat keinen Neuigkeitswert, doch seit der zweiten Amtszeit von Donald Trump und dem Triumph der „Broligarchie“ (Harrington 2024) scheint sie eine neue Ebene erreicht zu haben.
In diesem Aufsatz argumentiere ich, dass unterschiedliche, im Kapitalismus entwickelte Ausbeutungsstrategien – sogenannte politökonomische Aneignungsprotokolle – zu einer enormen Konzentration von Macht geführt haben, so dass eine kleine Anzahl an Akteuren in die Lage versetzt wurde, weltweit demokratische Gemeinwesen zu bedrohen.
An den drei Beispielen: Supplychain-Kapitalismus, Plattform-Merkantilismus und KI-Coup entwickle ich die „Politische Ökonomie der Abhängigkeiten“, um besser über Macht in der Wirtschaft sprechen zu können.
Einleitung
In einem Interview vom März 2024 sprach Sam Altman, CEO von OpenAI – der mächtigsten KI-Firma der Welt –, einen Satz aus, der ihm sofort unangenehm wurde. Er sagte: „Der Weg zu AGI sollte ein gigantischer Machtkampf sein.“ (Friedman 2024). AGI („Artificial General Intelligence“) markiert innerhalb der Branche die Erreichung von menschengleicher, genereller Maschinenintelligenz und ist das offizielle Ziel aller KI-Start-ups und -Konzernabteilungen. Altman korrigierte sich schnell: Er wünsche sich diesen Machtkampf nicht, aber er erwarte ihn.
Der Satz fällt an der Stelle, als es im Interview um seinen eigenen Machtkampf um die Kontrolle von OpenAI geht. Wenige Monate zuvor, im November 2023, feuerte ihn das Board des Unternehmens überraschend als Geschäftsführer. Die Nachricht verbreitete sich wie ein Lauffeuer und da das Board nur sehr vage Andeutungen über die Gründe machte, spekulierte die halbe Welt über den plötzlichen Rausschmiss (The Verge 2024).
Es ist wichtig, dabei zu verstehen, dass OpenAI keine Firma wie andere Firmen ist. Sie wurde bewusst als Non Profit Organisation (NGO) gegründet, um ethisch verantwortungsvolle KI-Forschung sicherzustellen, doch unter Altman etablierte sie einen For-Profit-Arm, um Milliarden Dollar an Venture Capital einsammeln zu können, die nötig wurden, um die immer teurer werdenden KI-Modelle zu finanzieren. Es waren die 10 Mrd. Dollar, die Microsoft in das Unternehmen investierte und in Form einer Gutschrift zur Nutzung ihrer Cloudinfrastruktur auszahlte, die die aufwändigen Modelle von OpenAI erst möglich gemacht hatten.

Doch das Board ist kein üblicher Unternehmens-Aufsichtsrat, sondern als Teil der NGO-Struktur den wissenschaftlichen und ethischen Standards der Forschung verpflichtet und hat über alle Geschäftsfelder das letzte Wort. Ein Rausschmiss des CEO ist der letzte Nothebel zur Sicherung dieser Kontrolle und genau so begründete das Board auch seine Entscheidung: Es habe das Vertrauen in Altman verloren.
Doch innerhalb weniger Tage änderte sich alles. Altman hatte es geschafft, einen Großteil der Mitarbeiter auf seine Seite zu ziehen, die auf einmal in einer Petition mit ihrer Kündigung drohten, und Microsoft, der wichtigste Geldgeber und Eigentümer der teuren Server-Infrastruktur, auf der OpenAI die Modelle trainiert und betreibt, stellte Altman in einer Blitzaktion als Chef einer neuen KI-Abteilung ein, mit der Bereitschaft, auch alle anderen OpenAI-Mitarbeiter aufzunehmen.
Das Board hatte in dem Moment keine andere Wahl mehr, als seine Entscheidung rückgängig zu machen. Altman kehrte nach weniger als einer Woche zurück auf seinen CEO-Posten und stattdessen wurde nun das Board von ihm neu aufgestellt.
Im bereits angesprochenen Interview reflektiert Altman überraschend offen, dass das Board rechtlich befugt war, ihn zu feuern, was seinen letztendlichen Sieg zu einer Art „Governance Failure“ mache.
Das ist eine erstaunliche Umschreibung für einen „Coup“.
Ein Jahr später hat sich Sam Altmans Versprecher als Prophezeiung herausgestellt. Die Jagd um die besten Modelle und – spätestens mit der Wahl Donald Trumps ins Weiße Haus – der Machtkampf in der Tech-Branche um politischen Einfluss und Macht waren in einem erstaunlichen Maß eskaliert.
Die Tatsache, dass die Branche technisch eher auf der Stelle tritt, hat dem Hype nicht nachhaltig geschadet. 2024 investierten die Techfirmen bereits über 100 Mrd. US$ in Rechenzentren (Lunden 2025) und Sam Altman sprach davon, die nächsten Jahre bis zu sieben Billionen Dollar Investitionen anzustreben (Hagey 2024).
Gleichzeitig hat sich das Thema politisiert. Schon unter der Biden-Präsidentschaft stand der Wettbewerb um KI- Vorherrschaft mit China im Mittelpunkt, doch mit dem Wiedereinzug von Donald Trump ins Weiße Haus sitzen zentrale Player der KI-Industrie nun direkt an den Schalthebeln der Macht und nutzen die Rivalität zu China als Investitions- und Deregulierungs-Argument.
Elon Musk, der die ersten zwei Monate der Trump-Präsidentschaft quasi als Co-Präsident auftrat und mit seiner eigenen Behörde DOGE (Department of Government Efficiency) nicht nur zigtausende Staatsbedienstete entließ, ganze Ministerien abwickelte und seinen eigenen Firmen wie Tesla, SpaceX und Star Link große Staatsaufträge zuschusterte, scheint nun die durch ihn geschröpften Behörden auch noch durch den KI-Chatbot seines eigenen Start-ups xAI ersetzen zu wollen. (Wong 2025 ).
AQ3 Doch Musk ist nicht der einzige Tech-Milliardär an der Quelle der Macht; da ist auch Peter Thiel, die graue Eminenz im Silicon Valley, der Trump schon in seiner ersten Amtszeit unterstützt hatte und bekennender Antidemokrat ist. Neben seinem alten Kompagnon Elon Musk und dem Vizepräsidenten JD Vance, für den er der intellektuelle Ziehvater ist, hat Thiel noch weitere 14 enge Kontakte in hohen Positionen der US-Administration (Alexander und Tarabay 2025).
Einer davon, David Sacks, ist jetzt offizieller „Crypto und KI-Tsar“ und kämpft auf oberster Regierungsebene gegen jegliche Form von Regulierung und Kontrolle der Tech-Branche. Doch der Kreis der Tech-Magnaten, die eng mit der neuen US- Regierung kooperieren – sei es als Berater oder ideologisch „alignter“ Business-Partner – ist viel größer: Marc Andreessen, einer der einflussreichsten Venture-Kapitalisten, Palmer Luckey und dessen militärischer Drohnenhersteller Anduril, Larry Ellison, der Gründer des Datenbankspezialisten Oracle, und einige andere gehören diesem Netzwerk rechter Tech-Milliardäre mit Einfluss in Washington an.
Aber auch Mark Zuckerberg (Meta), Jeff Bezos (Amazon) und Sundar Pichai (Google) ringen um Einfluss im Weißen Haus und ließen sich dafür sogar als „Spalier“ auf Donald Trumps Inauguration fotografieren ( Abb. 11.2 ) – eine so ikonische wie unwirkliche Unterwerfungsgeste aus Zeiten von Königen und ihren Tafelrunden.

Auch Sam Altman sucht die Nähe zu Trump und verkündete Anfang 2025, mit ihm zusammen das Projekt „Stargate“, ein 500-Mrd.-Dollar-Investmentpaket in KI-Infrastruktur, auf den Weg zu bringen (OpenAI 2025a) sowie Mitte 2025 ebenfalls große Regierungsaufträge (Schiffer 2025). Neuerdings hat auch Jensen Huang, Chef von Nvidia, Trumps Ohr und darf in die Handelsbeziehungen mit China eingreifen (Mickle 2025).
Doch der Friede bröckelt: Sam Altman und Elon Musk – als damaliger Mitgründer von OpenAI – sind alte, jetzt verfeindete Weggefährten und Musk hat mehrere Klagen gegen OpenAI laufen und kritisiert das Stargate-Projekt öffentlich. Musk selbst musste sich inzwischen aus der Regierungsarbeit herausziehen, um sein Unternehmen Tesla zu retten, das als Marke national und international unter Druck geriet, nachdem sich sein Agieren als DOGE-Chef als sehr unpopulär erwies (Guerra; Rameswaram 2025).
Bei einem Meeting Trumps mit hohen Militärs im Weißen Haus wunderten sich die anwesenden Generäle, als plötzlich die Tür aufging und Mark Zuckerberg in den Raum trat, um Trump etwas zu fragen, fast so als wäre er der Mitbewohner (Times of India 2025).
Es ist unklar, in welche Richtung sich das Gerangel um die Plätze an der Sonne noch entwickelt, aber eines steht fest: Der Technologiesektor ist im Herzen der Macht angekommen, hat alle Scham abgelegt und kämpft jetzt mit offenem Visier um Vorherrschaft von was auch immer da gerade am Entstehen ist.
Doch was ist da am Entstehen?
Um zu verstehen, warum Technologie und Politik plötzlich zu einer Art Real-Live „Game of Thrones“ verschmolzen sind und wo uns das hinführt, müssen wir viel grundlegender verstehen, wie Akteure in Technologie, Wirtschaft und Politik gelernt haben, Macht zu organisieren und welche Rolle KI darin einnimmt.
Dafür sind zwei Dinge notwendig: Es braucht zum einen eine Theorie der Macht, also eine politische Ökonomie, und zum anderen braucht es eine historische Situierung des aktuellen Moments: Welche Strukturen haben uns hierhergeleitet?
Ich versuche beides in diesem Text miteinander zu verflechten, indem ich die drei prägenden politökonomischen Paradigmen der letzten Jahrzehnte analysiere und theoretisiere:
- den Supplychain-Kapitalismus, der er seit den 1980er Jahren unsere globalisierte Wirtschaft organisiert
- den Plattform-Merkantilismus, der seit den 2010er Jahren unser Konsumleben auf den Kopf gestellt hat
- den sich ankündigenden, teils vollzogenen KI-Coup, der uns seit der Veröffentlichung von ChatGPT im Herbst 2022 in ein völlig neues Paradigma stürzt.
Im letzten Teil, in der Analyse von KI als Coup, wird dann hoffentlich klar, welches politökonomische Paradigma dort am Entstehen ist und warum diese Entwicklung sich nicht mit demokratischen Gesellschaften verträgt.
Der Supplychain-Kapitalismus
Das erste politökonomische Paradigma, über das ich sprechen möchte, ist der „Supplychain-Kapitalismus“. Er wurde in den 1980er Jahren popularisiert und bestimmt bis heute die Struktur unserer globalen Wertschöpfungsketten.
Grob gesagt, lagert im Supplychain-Kapitalismus ein sogenanntes „Leitunternehmen“ einen Teil seiner Aufgaben oder Vorprodukte oder sogar die gesamte Produktion an Zuliefererfirmen aus, die oft im Ausland sitzen. Über die Zeit differenzierten sich die Lieferketten immer weiter aus, bis sich ein weit verflochtenes und recht dynamisches Netzwerk an global situierten Zulieferfirmen entwickelt hatte, mit Schwerpunkten in China, Indonesien, Vietnam und Korea, was vor allem zwischen den 1990er Jahren bis heute zum dortigen Wirtschaftswachstum beigetragen hat. Gleichzeitig wurden westliche Markenunternehmen materiell entkernt und bestehen beinahe nur noch aus Marketing-Abteilungen für Produkte, die von anderen Firmen hergestellt werden (Klein 1999).
Anna Tsing erzählt in ihrem Buch „The Mushroom at the End of the World“ (Tsing 2015) den Aufstieg der Supplychains so: Als 1853 amerikanische Kanonenboote an der Küste vor Japan die Öffnung der japanischen Volkswirtschaft für den internationalen Handel erzwangen, sorgte das dort für einen politischen Umsturz und führte zu einer rapiden Verwestlichung der japanischen Kultur. Es entwickelte sich schnell eine moderne Ökonomie mit Fabriken, Banken und Handel. Anfang des 20. Jahrhunderts formten sich bereits die ersten Konglomerate, also Firmenstrukturen, die Unternehmen mit unterschiedlichen Funktionen unter einem Konzerndach etablierten. Dabei ging es darum, die Industrieproduktion mit starken Handelsunternehmen zu flankieren und mittels hauseigener Banken zu finanzieren. Nach dem verlorenen Zweiten Weltkrieg formierten sich die Konglomerate neu als »Enterprise Groups« und fingen an, Zulieferer in anderen Ländern zu gründen. Finanziert wurde das durch die Bankenkredite, die die Mischkonzerne an die gegründeten Zulieferer und zusammen mit eigenem Know-how weiterreichten. Die Zulieferer waren damit zwar formell unabhängig, aber wirtschaftlich doch abhängig, sodass sie bequem aus Japan gesteuert werden konnten.
Die Vorteile waren vielfältig: man konnte auf die Ressourcen des jeweiligen Landes zugreifen, ohne politische oder öffentlichkeitsbedingte Risiken einzugehen. Der Zulieferer übernahm formell die Verantwortung für Arbeiter:innen und Umwelt und kapselte die sich daraus ergebenden Risiken und potenziellen Kostenfaktoren vom Leitunternehmen ab. Oder wie es ein Manager von Disney einmal ausdrückte: »We don’t employ anyone in Haiti« (Klein 1999).
Gleichzeitig konnten die Leitunternehmen die Zulieferer schnell austauschen, etwa wie im von Tsing geschilderten Beispiel, die Holzarbeiter:innen von den Philippinen schnell nach Indonesien übersetzten, wenn der Wald knapp wurde (vgl. Tsing 2015, S. 116). Das bedeutet, dass die Zulieferer in eine kompetitive Situation versetzt wurden, die ihre Verhandlungsmacht mit den Leitunternehmen von vornherein begrenzte (Danielsen 2019).
Ein weiterer Faktor waren Einfuhrbeschränkungen in den USA, die aus Angst vor der immer größer werdenden japanischen Konkurrenz eingerichtet wurden. Südkorea war eines der ersten Länder, das vom frühen Supplychain-Boom durch japanische Unternehmen profitierte und entsprechend eine eigene industrielle Basis ausbauen konnte.
Diese konnte dann wiederum dazu genutzt werden, um Produkte von dort in die USA zu verschiffen und so die Einfuhrbeschränkungen zu umgehen. Die japanischen Leitunternehmen achteten dabei sehr genau darauf, dass Südkorea immer einen oder zwei technologische Schritte hinter den japanischen Konzernen verblieb. Gleichzeitig begannen die Zulieferer in Korea ihrerseits, weniger anspruchsvolle Arbeiten an Zulieferer in anderen Regionen auszulagern. Das Modell begann sich global zu streuen. In Japan wurden diese Supplychain-Verzweigungen mit der Metapher der »Fliegenden Gänse« beschrieben. Die „Leitgans“ fliegt voraus, die anderen sortieren sich dahinter, aber alle fliegen in eine Richtung.
Unter dem Druck des Erfolgs der japanischen Industrie und ihrem Supplychain-Modell begannen in den späten 1980er Jahren auch amerikanische Investor:innen die US-Industrie umzubauen. Unternehmensfusionen, Aufkauf durch Hedgefonds und das Abspalten und Auslagern von unwirtschaftlichen Unternehmensteilen waren bis einschließlich der gesamten 1990er Dauerthema in den USA und mit etwas Zeitverzug auch in Europa.
Eine einfache Theorie der Macht
Um Machtstrukturen genauer zu analysieren, erweist sich der Rückgriff auf den viel zu wenig rezipierten Aufsatz „Power-Dependence Relations“ von Richard M. Emerson aus dem Jahr 1962 als nützlich (Emerson 1962).
Emerson definiert die Macht zwischen Akteuren als die wechselseitige Abhängigkeit dieser Akteure. Macht ist bei ihm immer ein interdependentes Verhältnis, bei dem die Macht des einen der Abhängigkeit des anderen entspricht.
Wenn A abhängig von B und B abhängig von A ist, dann ist die Macht von A über B Bs Abhängigkeit von A und umgekehrt.
Dass Abhängigkeit und damit auch Macht immer wechselseitig gedacht wird, widerspricht dabei nicht der Beobachtung, dass es Machtungleichgewichte gibt, denn A kann in diesem Modell durchaus weit weniger abhängig sein von B als B von A (Emerson 1962).
Stellen wir uns eine ausgeglichene Beziehung vor: A und B sind hier zwei Kinder aus der Nachbarschaft. Die beiden Kinder spielen gern zusammen, denn allein spielen ist langweilig. Sie sind also beide von ihrer wechselseitigen Kooperation abhängig. Würde A sich weigern, mit B zu spielen, könnte B sein Ziel (gemeinsames Spielen) nicht erreichen. Aber A könnte es ebenso wenig.
Nun zieht eine neue Familie in die Nachbarschaft, und A lernt C kennen, das gleichaltrige Kind der neuen Familie. Die beiden freunden sich an. Das verändert auch die Beziehung zwischen A und B, da A jetzt eine neue Spielpartnerin hat. A hat nun mehr Macht über B, da er weniger abhängig von B ist als B umgekehrt von A. B müsste nun einen Balanceakt vollziehen, um dieses Machtungleichgewicht wieder auszutarieren. Dafür hat sie vier Optionen.
- Balanceakt 1: Sie kann ihre eigene Motivation, mit A zu spielen, zügeln (»A ist eh doof«).
- Balanceakt 2: Sie kann sich eine alternative Ressource erschließen, also zum Beispiel eine andere Spielkameradin finden (eine Spielkameradin D zum Beispiel).
- Balanceakt 3: Sie kann sich selbst als Spielkameradin für A wieder attraktiver machen (indem sie zum Beispiel in ein neues Legoset investiert), damit A wieder lieber zu B zum Spielen kommt.
- Balanceakt 4: Sie kann As Zugang zu alternativen Ressourcen (in diesem Fall also zu C) versperren. Sie kann zum Beispiel Cs Familie überreden, wieder wegzuziehen (schwierig) oder sich mit C verbünden (leichter).
Dabei gilt: Abhängigkeiten und damit Macht sind immer latent. Wie groß eine Abhängigkeit wirklich ist, weiß man nicht, bevor sie „getestet“ wurde. Insofern sind Abhängigkeiten auch immer ein Stück weit imaginiert und ob die erwartete Abhängigkeit wirklich der materiellen Abhängigkeit entspricht, erweist sich erst im Konfliktfall, also wenn A etwas tut, was den Interessen von B entgegensteht oder umgekehrt (Emerson 1962).
Wenn wir dieses einfache Framework auf die Zulieferketten anwenden, ergibt sich ein klareres Bild: Um einen Nike-Schuh herzustellen, sind alle Akteure (das Leitunternehmen sowie alle Zulieferfirmen) wechselseitig voneinander abhängig. Jedoch gibt es Unterschiede: Jeder Einzelne der Zulieferer – egal ob er Stoffe, Plastik oder Kordeln herstellt – ist aus Sicht des Leitunternehmens recht einfach austauschbar (Balanceakt 2). Es gibt viele konkurrierende Unternehmen und selbst, wenn es sie nicht gäbe: das Wissen, um Stoffe, Plastik und Kordeln herzustellen, ist schnell ins Werk gesetzt.
Das Leitunternehmen hingegen, Nike, betreut zwar nur die Marke und andere Rechte, aber diese Rechte sind dank internationaler Abkommen wie TRIPS (Agreement on Trade-Related Aspects of Intellectual Property Rights) und durch die WTO (World Trade Organization) global geschützt (Balanceakt 4). Die Leitunternehmen kontrollieren daher monopolistisch den Zugang zur Wertschöpfung. Für die Zulieferer ergibt sich dadurch eine enorme Abhängigkeit, denn ohne den Zugang zu Nikes Verkaufsnetzwerk und seiner »Brand-Recognition« sind die Produktionskapazitäten der Zulieferer völlig nutzlos. Dadurch ist Nike der einzige Akteur in diesen wechselseitigen Beziehungen, der weniger von den anderen abhängig ist, als diese von ihm. Die »Fliegenden Gänse« sind also in Wirklichkeit eine Hierarchie der Macht, die von einem durch globale Gesetzgebung geschützten Leitunternehmen angeführt und ausgebeutet wird. Je tiefer man in die Verästelung der Lieferketten hinabsteigt, desto austauschbarer werden die Unternehmen, die, in Ableitung davon, weniger fähig sind, durch Effizienzgewinne erarbeitete Margen gegenüber dem Leitunternehmen zu verteidigen.
Empirisch lässt sich dieses Ungleichgewicht gut am Smartphone-Markt beobachten. Seit der Markt für iPhones gesättigt ist und die Verkaufszahlen stagnieren, sinkt entsprechend der Umsatz bei Foxconn, dem chinesischen Fabrikanten der iPhones, während Apple, das vor allem die Marke und die Patente kontrolliert, seinen iPhone-Umsatz um 20 % steigern konnte (Danielsen 2019).
Im Supplychain-Kapitalismus gibt es nicht mehr nur die Ausbeutung von Arbeiter:innen durch Kapitalist:innen, wie es Marx beschrieb, sondern auch die Ausbeutung von Kapitalist:innen untereinander. Es entsteht eine globale Hierarchie der Kapitalist:innen, bei der sich nur noch die Zulieferer mit einfachen Arbeiter:innen herumschlagen müssen. Diese Zuliefer- Kapitalist:innen sitzen meist in eher strukturschwachen Ländern und müssen, um überhaupt am Spiel der globalen Lieferketten teilnehmen zu dürfen, ihre Produktivitäts-Margen den Leitunternehmen opfern. Zu diesem Schluss kommt zum Beispiel Dan Danielsen:
»The fierce competition among developing-country suppliers in many business sectors will likely require supplier firms to make these innovations to gain access to or remain competitive in global supply chains with gains likely captured by buyer firms or shared across global chains«
(Danielsen 2019).
An einer anderen Stelle spricht Tsing über Skalierbarkeit. Skalierung ist für Tsing ein „nicht-transformatives Wachstum“. Ein Wachstum also, das zwar neue Verbindungen eingeht, sich von diesen Verbindungen aber nicht verändern lässt. Eine skalierbare technische Infrastruktur ist zum Beispiel eine, bei der es strukturell kaum einen Unterschied macht, ob sie von 10 oder 10 Mio. Menschen verwendet wird. Die meisten modernen Geschäftsmodelle basieren auf einer solchen Idee von Skalierung bzw. Skalierbarkeit.
Tsing wendet ein, dass diese Skalierbarkeit immer einen Preis hat. Das zu Skalierende muss zunächst, so Tsing, immer aus einem Gewebe von Verbindungen herausgelöst werden. Verbindungen müssen gekappt werden, um Skalierbarkeit zu gewährleisten. Tsing gibt das Beispiel von Zuckerrohrplantagen in der Kolonialzeit in Südamerika. Die Portugiesen merkten bald, dass eine wesentliche Voraussetzung der Skalierbarkeit die Entwurzelung und damit die Austauschbarkeit der Elemente ist:
»They crafted self-contained, interchangeable project elements, as follows: exterminate local people and plants; prepare now-empty, unclaimed land; and bring in exotic and isolated labor and crops for production. […] The interchangeability of planting stock, undisturbed by reproduction, was a characteristic of European cane. … Under these conditions, workers did, indeed, become self-contained and interchangeable units«
(Tsing 2015).
Die Herstellung von Austauschbarkeit erweist sich als wesentliches Basiselement kapitalistischer Wachstumskonzeptionen. Und diese Austauschbarkeit wird über das Abkapseln von Verbindungen und das Reduzieren von Abhängigkeiten hergestellt. Erst diese »relationale Dematerialisierung« reduziert die Reibung in den Prozessen und macht globale Lieferketten überhaupt möglich. Der Schiffscontainer ist somit nicht nur das logistische Kernstück der Globalisierung. Er ist auch zentrales Sinnbild einer Form von »relationaler Dematerialisierung«, die alle unnötigen Verbindungen abkapselt und jedes physische Gut zu einer austauschbaren Einheit macht. Der ISO-Container ist absolut austauschbar, das ist sein ganzer Sinn.
Relationale Dematerialisierung ist auch, was hinter Emersons Balanceakten steckt. Die Balanceakte errichten Hürden der eigenen Austauschbarkeit (Balanceakt 3 und 4) und/oder organisieren andere in bessere Austauschbarkeit (Balanceakt 1 und 2). Wichtig ist nur, dass man seine relative Position im Netz verbessert.
Relativ austauschbar sind – wie zuvor bereits beschrieben – eben auch die Zulieferer. Der Supplychain-Kapitalismus funktioniert, indem das Leitunternehmen eine Austauschbarkeits-Hierarchie etabliert, an dessen Spitze es sich setzt und sie von dort dominiert.
Der Supplychain-Kapitalismus ist nicht nur eine Managementtechnik oder eine materielle Kette von interdependenten Firmen, sondern eine Art Rezeptur der Margenextraktion, ein politökonomisches Aneignungsprotokoll.
Der Aufstieg des Plattform-Merkantilismus
Mit der Popularisierung des Internets erscheint ab den späten 2000er Jahren ein neues, relevantes politökonomisches Protokoll auf der Bildfläche: der „Plattform-Merkantilismus“.
Der Begriff »Plattform« kommt ursprünglich aus dem Französischen und ist eine Zusammensetzung aus altfranzösisch »plat« (flach) und »forme« (von lateinisch: forma). Er wurde in der frühen Neuzeit vor allem in Bezug auf eine militärische Architektur verwendet: eine etwas erhöhte Fläche, die sich gut eignete, Katapulte und später Kanonen darauf zu positionieren. Kanonen sollten einerseits erhöht stehen, um eine optimale Reichweite zu erzielen, andererseits musste gewährleistet sein, dass sie schnell austauschbar waren. Die Austauschbarkeit war von Anfang an entscheidend.
Die technische Verwendung des Plattformbegriffs entwickelte sich zunächst in der Computerindustrie. IBM, der damalige Platzhirsch auf dem Markt, verkaufte oder vermietete seit den frühen 1960ern seine kühlschrankgroßen Mainframe-Computer ausschließlich an große Unternehmen, Universitäten und Behörden. Die erste Computerplattform entwickelte IBM Mitte der 1960er mit dem System/360. Das Unternehmen standardisierte die Schnittstellen des Systems und hielt sie auch in künftigen Weiterentwicklungen rückwärtskompatibel, sodass Software für das eine Modell auch auf anderen, sogar zukünftigen Modellen ähnlicher Bauart funktionierte und sich Software-Entwickler:innen an ihnen orientieren konnten. Vorher vertrieb IBM Software und Hardware als integrierte Gesamtpakete. Mit dem Personal Computer (erst Apple II 1977, dann IBM PC 1981) popularisiert sich die Verwendung des Begriffs Plattform für technische Systeme, für die Drittanbieter Software schreiben können.
Eine Plattform ist eine Infrastruktur zur Ermöglichung von Austausch. ‚Ermöglichung von Austausch‘ lässt sich auf zweifache Weise lesen. Zum einen sind Plattformen Orte, an denen man sich austauscht: der Ort, an dem man Geschichten teilt, Handel betreibt, flirtet oder ein Taxi ruft. Zum anderen sind Plattformen Orte der Austauschbarmachung. Durch Standardisierung werden alle Dinge auf der Plattform vergleichbarer und damit austauschbarer gemacht und das gilt auch für die Benutzer:innen selbst. An Plattformen kann man nur als austauschbare, in gewisser Weise standardisierte Variante seiner selbst teilnehmen. So wie wir Produkte, Informationen und Unterhaltung auf Plattformen durch die Standardisierung leichter finden können, erlaubt die Standardisierung auch anderen, uns selbst über Suchen oder Empfehlungsalgorithmen zu finden und sich mit uns zu verbinden.
Beide Weisen des Austauschs hängen zusammen: Die Austauschbarkeit aller ist das, was den Austausch für alle vereinfacht und die Menge an potenziellen Verbindungen für jeden Einzelnen erweitert, denn die nächste Fahrerin, die nächste Unterkunft, das nächste Date ist nur einen Klick oder Rechts-Swipe entfernt.
Die politische Ökonomie der Abhängigkeiten
Stellen wir uns die Gesellschaft als multidimensionales Netzwerk von Abhängigkeiten vor, in dem die Akteure wechselseitig abhängig voneinander sind und bei dem die Dimensionen die unterschiedlichen Arten der Abhängigkeit repräsentieren, seien es notwendige materielle Infrastrukturen, Informationen, Arbeit, Produkte, Transaktionen, Aufmerksamkeit oder Care.
In dieses Netzwerk kann man dann mit unterschiedlichen Zoomstufen reinschauen.
Auf der Ebene des Haushalts kennen wir uns alle aus. Wir können die Spülmaschine nicht anstellen, weil wir erst noch Essen machen müssen, was aber nicht geht, weil die Teller nicht abgespült sind. Wir stellen fest: Abhängigkeiten sind verknüpft, also vernetzt und vertrackt und einen Haushalt (altgriechisch: „Oikos“) zu führen, bedeutet in erster Linie, materielle Abhängigkeiten zu managen.
Alle Handlungen sind vom Ergebnis anderer Handlungen abhängig, Menschen sind voneinander abhängig, Infrastrukturen, Institutionen, Bräuche und Sprache beschreiben interdependente Abhängigkeiten. Das Netz der Abhängigkeiten ist riesig, kleinteilig und filigran verzweigt und nur mit einem kleinen Teil davon – der, in dem die Abhängigkeiten Preise haben – befasst sich die (neo-)klassische Ökonomie.
Schaut man genauer hin, sieht man viele unterschiedliche Abhängigkeitsformationen als Beziehungsweisen zwischen den Menschen: Care, Lohnarbeit, Konsum, Liebe, Lieferketten, Status-Hierarchien, Gewalt etc. Wir alle sind ständig damit beschäftigt, unterschiedlichste Abhängigkeitsdimensionen zu navigieren und unser Geld hilft bei vielem, aber längst nicht bei allem davon weiter.
Auch wenn wir unsere Sicht auf den Kapitalismus beschränken, können wir die Abhängigkeits-Dimensionen noch differenzierter auflösen. Dann sieht man finanzielle, materielle, personelle und politische Abhängigkeiten und kann beobachten, wie die wiederum auf die internen Strukturen der Firmen zurückwirken (Pfeffer; Salancik 1978).
Schauen wir auf die Wirkung von Unternehmen auf die Gesellschaft, sehen wir wie jede neue Produktkategorie neue, spezifische Abhängigkeiten in das Netzwerk einführt, denn Produkte finden ihren Platz in unseren Lebensritualen und Workflows, die dann ohne sie nicht mehr funktionieren.
Man kann sodann raus-zoomen und stellt fest, dass sowohl Haushalte als auch Unternehmen an allerlei Infrastrukturen gekoppelt sind. Straßen, Schulen, aber eben auch Geschirrspülmittelhersteller und Obstplantagen. Das Netzwerk der Abhängigkeiten wird in kapitalistischen Ökonomien entlang allerlei privater, aber auch einer Menge öffentlicher Infrastrukturen organisiert und diese Infrastrukturen nehmen jeweils relativ netzwerkzentrale Stellungen im Abhängigkeitsnetzwerk ein und sind selbst wieder in ein Netz von Abhängigkeiten verstrickt.
Das Netz der Infrastrukturen ist mit dem Netz der Abhängigkeiten eng verflochten, denn es hat sich in einer Art stetigen Ko- Evolution mit ihm zusammen entwickelt. Abhängigkeiten motivieren die Errichtung von Infrastrukturen und Infrastrukturen kreieren neue Abhängigkeitsbeziehungen.
Zoomen wir noch weiter raus, sehen wir aus dieser Makroperspektive das Netzwerk der Abhängigkeiten am klarsten als Handelsströme zwischen den Staaten und können z. B. an Donald Trumps Zollpolitik, an Russlands geostrategischer Gaspolitik oder Chinas Belt and Road Initiative nachvollziehen, wie Macht unter Staaten entlang von aggregierten Abhängigkeitsrelationen und ihren Infrastrukturen verhandelt wird und sehen, wie sich in diesen Strukturen noch die kolonialistischen Ursprünge des globalen Handelssystems abbilden (Weber et al. 2021).
Relationale Dematerialisierung durch Netzwerkmacht
Ähnlich wie die Leitunternehmen des Supplychain-Kapitalismus kreieren Plattformen eine Abhängigkeitshierarchie zwischen sich und den Nutzenden, denn der generellen Austauschbarkeit der einzelnen Verbindung steht eine große Nicht- Austauschbarkeit gegenüber: die des Graphen. Ein Graph, oder genauer: ein »Netzwerkgraph«, ist erstmal die Beschreibung eines Netzwerkes. Die Nutzenden erleben den Graphen als je einzigartiges Netzwerk an Verbindungen, das sie an die Plattform bindet. Nur dort postet der geliebte Filmstar X, nur dort hat man sich die Reichweite aufgebaut, nur dort bekommt man Fachdiskurse zu Thema Y mit etc. Und genau in dem Unterschied zwischen austauschbarer Verbindung und unaustauschbarem Graphen residiert die Macht der Plattformen.
Diese Macht wird in der ökonomischen Theorie gerne als »Netzwerkeffekt« oder »Netzwerkexternalität« bezeichnet, doch mit David Singh Grewal bezeichne ich diese Macht als »Netzwerkmacht« (vgl. Seemann 2021, S. 104 ff.; Grewal 2008).
Sie sorgt dafür, dass Menschen einerseits einen starken Anreiz haben, sich großen Netzwerken anzuschließen (es locken viele potenzielle Verbindungen) und bindet sie andererseits langfristig an das Netzwerk (der sogenannte »Lock-in-Effekt«).
Die Macht der Plattform über dich ist deine Abhängigkeit gegenüber ihrem Graphen – also im Zweifel die Abhängigkeit für den Zugang zu deinem sozialen oder professionellen Umfeld, zu Informationen und News, zu bestimmten Dienstleistungen, Produkten oder deinem Zahlungsverkehr, während deine Macht gegenüber der Plattform maximal relational dematerialisiert ist. Jedes Geschäftsmodell von Plattformen besteht in der Ausbeutung dieser Abhängigkeiten, sei es durch eine einfache Bezahlschranke oder Werbekund:innen, die Geld für den Zugang zu den „Eyeballs“ der Nutzenden bezahlen, möglichst durch Datenauswertung genau „getargetet“.
Für die dabei genutzten Taktiken hat sich der Begriff „Enshittification“ eingebürgert (Doctorow 2023). Der bekannte Science-Fiction-Autor und Netzaktivist Cory Doctorow beschreibt damit einen Prozess des mutwilligen kommerziellen Vandalismus der Plattformen an sich selbst, der aus dem Zwang für die Plattformunternehmen motiviert ist, wachsende Renditen auch bei abgeflautem Nutzerwachstum zu erwirtschaften. Weil die Renditeerwartung im Tech-Sektor hoch ist, muss aus denselben Nutzenden mehr Geld extrahiert werden und das geht nicht, ohne den Dienst für alle zu verschlechtern.
Der Mechanismus geht so, dass im ersten Schritt Geschäftskunden und Nutzer zum gegenseitigen Vorteil zusammengebracht werden. Im zweiten Schritt wird dann der dadurch entstandene Mehrwert bei den Geschäftskunden (Uber-Fahrer, Shop-Betreiber auf Amazon Marketplace, Werbekunden bei Google und Facebook) durch immer schlechtere, ausbeuterische Konditionen abgeschöpft, bis dann im dritten Schritt der Mehrwert auch bei den Nutzenden immer stärker abgeschöpft wird, indem der Service teurer und schlechter gemacht wird. Am Ende landet der Großteil des Mehrwerts der Plattform als Rendite bei den Aktionären.
Herrschte im klassischen Kapitalismus, wer über „die Produktionsmittel“ verfügte, so ist es im digitalen Kapitalismus derjenige, der über die „Mittel der Verbindung“ verfügt. Plattformen haben sich erfolgreich zwischen Shop und Kunden, zwischen Fahrer:in und Fahrgäste und Informationslieferant und Informationssuchenden gestellt und kassieren nun auf beiden Seiten Wegzoll.
Doch der abgeschöpfte Mehrwert beschränkt sich längst nicht mehr nur auf Geld. Silicon Valley hat unsere öffentliche Sphäre in Beschlag genommen und sitzt jetzt an den subtilen Schalthebeln der algorithmisierten Sichtbarkeit von Informationen und Meinungen und exerziert damit immer ungenierter auch politische Macht.
Elon Musk, der 2022 Twitter übernahm, transformiert die Plattform von einem der wichtigsten Orte für digitale Öffentlichkeit zu einer „Nazipropagandawaffe“, indem er gezielt Rechtsradikale wieder auf die Plattform holte, Journalisten zensiert, gerichtliche Verfahren gegen NGOs führt und den Empfehlungsalgorithmus für rechte Inhalte und vor allem für seine eigenen Posts optimiert, mit denen er nun allerlei Verschwörungstheorien über den „Woke Mind Virus“ und das „Great Replacement“ an sein Millionenpublikum promotet (Maher 2025; Prithvi 2024). Die politische Macht, die Musk durch X gekauft hat, verwandelt er wiederum in Staatsaufträge und Deregulierung seiner Firmen, also in Geld (McNicholas und Poydock 2025).
Kapitalismus vs. Merkantilismus
Das Supplychain-Modell folgt noch dem klassischen Aneignungsprotokoll des Kapitalismus: Das Eigentum an Produktionsmitteln (Kapital) wird staatlich geschützt und etabliert eine hinreichende Nichtaustauschbarkeit (ein mehr oder weniger lokales Monopol), während das Unternehmen die Aufgaben der Arbeiter:innen hinreichend standardisiert, um ihre Austauschbarkeit zu gewährleisten, sie also relational dematerialisiert.
Die Tatsache, dass im Supplychain-Modell die Produktionsmittel der Leitunternehmen immaterielle Werte wie Marken- und Verwertungsrechte sind, statt Gebäude und Maschinen, ist zwar eine historische Neuerung; sie tastet das Grundprinzip des Kapitalismus aber nicht an. Es zieht mit der Netzwerkmacht von globalen Marken und anderen international geschützten Immaterialgütern eine neue Ebene in den Kapitalismus ein und wendet sein Prinzip der Ausbeutung einfach auf die Zulieferer statt die Arbeitenden an. Weil das immaterielle Kapital (weltweit geschützte Immaterialgüterrechte) in der Praxis noch unaustauschbarer ist (durch Handelsabkommen relational materialisiert), als es das materielle Kapital (Gebäude, Maschinen etc.) je war, etablieren sich globale Ausbeutungsverhältnisse.
Das politökonomische Aneignungsprotokoll der Plattform weicht hier entscheidend ab. Indem es als Machtgrundlage die Unaustauschbarkeit des durch ihn kontrollierten Graphen etabliert, macht es sich vom Ordnungsregime des Eigentums – und damit der Durchsetzungsmacht des Staates – ein gutes Stück unabhängig (Seemann 2021; Wark McKenzie 2021). Plattformen haben kein rechtliches Eigentum an ihrem Graphen. Es gibt keine Möglichkeit, Dritten gegenüber einen Rechtsanspruch für einen Graphen zu reklamieren, denn Interaktionszusammenhänge sind rechtlich nicht eigentumsfähig. Das brauchen Plattformen aber auch nicht. Ihre Macht basiert auf der direkt ausgeübten Kontrolle über den Graphen mittels ihrer technischen Infrastruktur (Seemann 2021, S. 117 ff.). Über diese können Plattformen zum Beispiel vorgeben, welche Arten von Interaktionen man auf ihnen durchführen darf (Infrastrukturregime), sie können Nutzende ein- und ausschließen (Zugangsregime), sie können mittels algorithmischer Kontrolle bestimmte Interaktionen wahrscheinlich oder unwahrscheinlich machen (Query-Regime) und einiges mehr. Nur dadurch sind sie fähig, Preise für eigentlich unknappe Güter verlangen zu können (Staab 2019).
Kapitalismus als Spiel um Netzwerkzentralität und Marge
In der Ökonomie der Austauschbarkeit können wir sowohl den Kapitalismus als auch den Merkantilismus nun als Spiele um Macht beschreiben, in denen alle Akteure ihre Abhängigkeiten managen müssen. Akteure, die nach Macht streben, versuchen dabei, andere von sich abhängig zu machen und/oder die eigenen Abhängigkeiten gegenüber anderen zu reduzieren. Das betrifft nicht nur Kapitalist:innen, sondern auch Arbeitende und Konsumierende.
Wir erleben Austauschbarkeit innerhalb eines Abhängigkeitsnetzwerks als Bypassbarkeit. Wenn ein Produkt austauschbar, d. h. „substituierbar“ ist, dann kann ich meine existierende Abhängigkeit bei Bedarf auf ein anderes Produkt verlagern (Balanceakt 2). In der mathematischen Graphentheorie spricht man von „Betweenness-Netzwerkzentralität“.
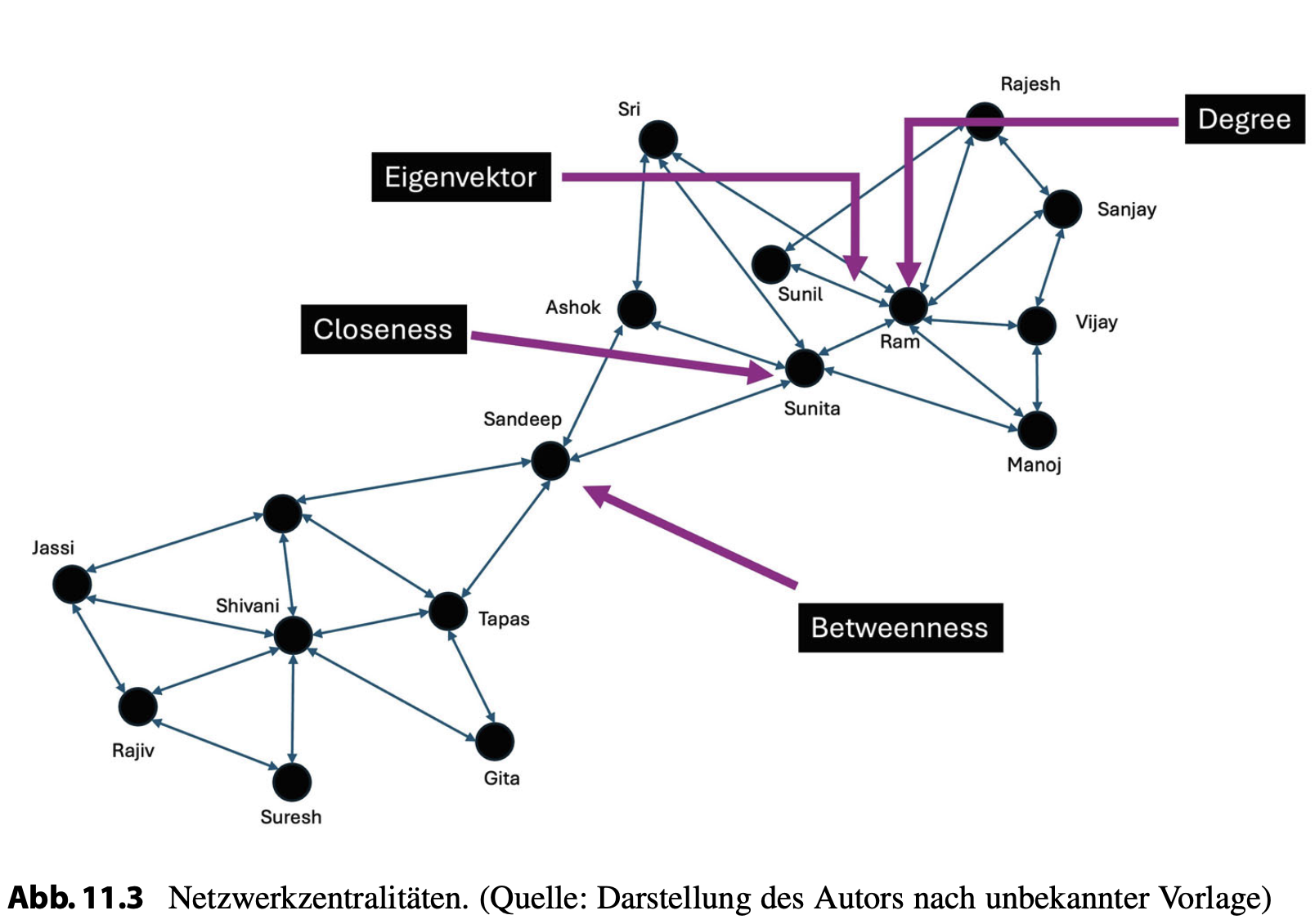
Man kann sich das bildlich so vorstellen, dass auf ein Unternehmen im Netzwerk der Abhängigkeiten viele bepreiste Inputlinien einströmen, während bepreiste Outputlinien zu den Abnehmern führen. Grundsätzlich gilt auch für einen Supermarkt, dass die Einnahmen langfristig die Ausgaben übersteigen müssen, aber ansonsten hat das Unternehmen viel Spielraum in dieser Situation.
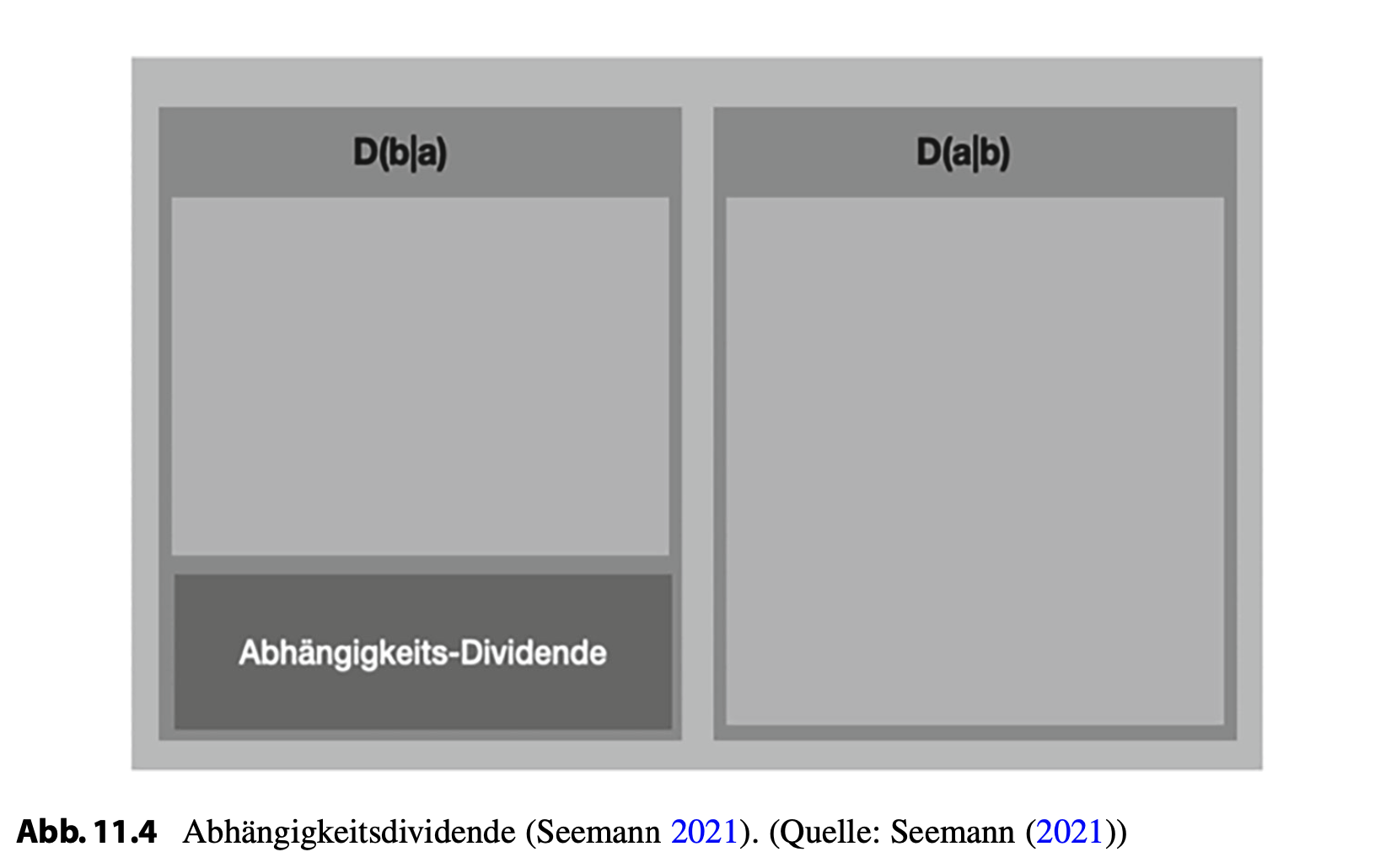
Um die Abhängigkeits-Dividende zu heben, kann man als Kapitalist die Inputlinien drücken: Lohndumping, Gewerkschaften zerschlagen, Wage Theft, Deskilling, Druck auf Zulieferer ausüben, vertikale Integration, Zahlungen zurückhalten etc. Oder man schraubt an den Outputlinien: Preise erhöhen, Verkaufsmengen reduzieren, Qualität reduzieren, Regulierungen missachten, Filialen schließen, Enshittification etc.
Das sind jeweils Balanceakte, weil die ausgebeuteten Akteure ab einem bestimmten Schmerzpunkt den Kanal kappen und versuchen werden, um das Unternehmen herumzurouten (Emerson: Balanceakt 2). Doch über Herstellung entsprechend hoher Betweenness-Netzwerkzentralitäten lassen sich Schmerzpunkte fast beliebig nach oben verschieben (Balanceakt 4). Wo Menschen die Pfadgelegenheiten ausgehen, sind sie gefangen.
Ausbeutung ist nicht etwas, das ausschließlich zwischen Kapitalisten und Arbeiter:innen passiert, wobei diese Form der Ausbeutung nach wie vor sehr zentral ist. Ausbeutung findet überall statt, wo in ungleichen Beziehungen Machtreservoirs zu heben sind und erfolgreiche Unternehmen zeichnen sich dadurch aus, Zugriff auf viele solcher Reservoirs zu haben.
Daraus leitet sich die zweite These ab: Im Kapitalismus misst sich die relative Macht eines Unternehmens nicht an Marktkapitalisation, Marktanteil, Umsatz oder Gewinn, sondern an der Marge.
Margen sind, grob gesagt, die Differenz zwischen dem Produktpreis und seinen Beschaffungs- oder Herstellungskosten, aber wir verstehen jetzt, dass alle Margen abgeschöpfte und akkumulierte Abhängigkeits-Dividenden sind.
Damit können wir das „Spiel“ des Kapitalismus so beschreiben: Jeder Akteur strebt danach, die eigenen Abhängigkeiten von anderen zu reduzieren und die Abhängigkeiten anderer von einem selbst zu maximieren. Ziel dabei ist immer, sich selbst möglichst alternativlos zu machen und die anderen relational zu dematerialisieren. Dabei werden unausgesprochene Austauschbarkeits-Hierarchien etabliert, über die auf die eine oder andere Weise Margen abgeschöpft werden können.
Bei diesem Spiel sind quasi alle Akteure des Kapitalismus gezwungen, mitzumachen. Kapitalisten, Leitunternehmen, Zulieferer und sogar viele Arbeitende untereinander, indem sie sich z. B. durch angeeignete Skillsets, inkorporiertes Orientierungswissen oder soziale Netzwerke im Unternehmen eine relative Betweenness-Position ergattern. Fast alle Einkommen (Gewinne, Boni, Löhne, Dividenden) sind auf die eine oder andere Art Margen aus diesen Austauschbarkeitshierarchien.
Vorsicht: Das ist kein Urteil über die Qualität oder die tatsächliche Notwendigkeit geleisteter Arbeit oder hergestellter Produkte oder Infrastrukturen. Im Gegenteil: Der Qualitätsmaßstab für „gute Arbeit“ innerhalb dieses Systems ist oft gerade ihre Austauschbarkeit. Austauschbarkeit von Arbeit ist von den Kapitalisten erwünscht und wird von ihnen aktiv hergestellt. Von Fords Fließband über Frederick Taylors „Scientific Management“ über den Supplychain-Kapitalismus bis zu den Lieferdienste-Apps des Plattform-Merkantilismus und der Automatisierung von Arbeitsprozessen durch KI (Rinta-Kahila 2018) geht es immer nur darum, Arbeit austauschbarer zu machen, sie relational zu dematerialisieren.
Der Kampf der Kapitalisten gegen Gewerkschaften ist ebenfalls ein Teil davon, denn sie sind Architekturen der Bündelung von Verhandlungsmacht (Balanceakt 4), was die Betweenness-Netzwerkzentralität der Arbeitenden gegenüber den Kapitalisten wirksam erhöht.
Der KI-Coup
Mit KI kündigt sich ein neues politökonomisches Paradigma an, aber so wie der Plattform-Merkantilismus neben dem Supplychain-Kapitalismus koexistiert, wird das politökonomische Protokoll des KI-Coups die bestehenden Paradigmen zwar enorm aufscheuchen, aber wohl nicht völlig ersetzen.
Wenn wir hier von „Künstlicher Intelligenz“ sprechen, dann meinen wir ganz konkret die „Generative Künstliche Intelligenz“ auf Basis der Transformer-Architektur, wie sie seit der Vorstellung von ChatGPT im Oktober 2022 in aller Munde ist (Seemann 2023). Ich will für diesen Text auch stellenweise das Abenteuer eingehen, die von den Entwickler:innen behaupteten Potenziale der Technologie ernstzunehmen, verweise aber auch entsprechend auf die spekulative Natur dieser „Imaginaries“.
Generative KI basiert auf dem schon länger etablierten „Machine Learning“ und auf Deep Neural Networks, die seit etwa 2012 eine allgemeine KI-Renaissance einleiteten. Dabei werden „künstliche neuronale Netzwerke“ mit enorm vielen Daten trainiert, im Fall von ChatGPT und Co. Tausende von Gigabyte an Text- und/oder Bilderdaten. Das Training benötigt viele Millionen Dollar teure Rechenleistung und verschlingt Unsummen an Energie – im Betrieb ist der Verbrauch etwas geringer.
Generative KI, insbesondere Large Language Models wie ChatGPT, Claude und Gemini, schaffen es, verblüffend plausible und oft brauchbare Antworten auf alle Fragen zu geben, die man den Chatbots stellen kann, was dazu führt, dass sie in allerlei Arbeits- aber auch private Nutzungsprozesse integriert werden.
In den letzten drei Jahren hat der Hype nur noch mehr Schwung bekommen und es werden Ressourcen in Volkswirtschaftsgröße auf die Weiterentwicklung dieser Systeme geworfen, was in einer ungeheuer beschleunigten Skalierung resultiert. Skalierung von Daten, Rechenzentren, Energiebedarfen und Investitionssummen.
Der primäre professionelle Einsatzzweck ist derzeit Software-Entwicklung, wo die Chatbots die Arbeit am Code enorm erleichtern und beschleunigen (Weber et al. 2024). Aber auch in anderen Branchen helfen LLMs, Dokumente, Briefe, Emails, Designs, Formulare, Verträge, Illustrationen und Übersetzungen zu erstellen. Dazu kommen Schüler:innen und Studierende, die damit Hausarbeiten und Abschlussarbeiten erstellen. Doch ein Großteil des Outputs von Generativer KI entsteht als unbestellter Content-Müll, der mittlerweile alle Ecken des Internets verstopft und für den sich der Name „Slop“ etabliert hat.
Keine Frage, die Chatbots sind populär, nicht nur im Arbeitskontext, sondern zunehmend auch privat. Sie geben Ratschläge, helfen mit technischen oder persönlichen Problemen, werden zu Freund:innen und Therapeuten-Ersatz.
Das alles, obwohl bekannt ist, dass auf sie kein Verlass ist. Selbst auf denselben Prompt gleicht keine Antwort der anderen und das viel zitierte „Halluzinieren“ ist nicht einfach ein Software-Bug, sondern die Funktionsweise des Systems. LLMs „halluzinieren“ am laufenden Band Zahlen, Daten, Personen, Rechts-Paragraphen, Softwarebibliotheken und Buchtitel herbei, sodass man den Output nie ungeprüft übernehmen kann, ohne unangenehme Überraschungen zu erleben (Seemann 2023).
KIs wird eine kompetenznivellierende Wirkung nachgesagt. Studien zeigen, dass vor allem performanceschwache Arbeitskräfte überdurchschnittlich vom Einsatz von KI profitieren (Etsenake und Nagappan 2024) und auch in der Breite der Bevölkerung hilft KI Menschen, die vorher Schwierigkeiten hatten, etwa einen Brief zu formulieren oder sich grafisch auszudrücken (Villasenor 2025). Manche sprechen gar von einer „Demokratisierung“ des Schreibens, Codens oder der Gestaltung. Und wer weiß, vielleicht haben wir ja bald allesamt eigene Assistenten, die uns alle Arbeit abnehmen?
Als die nächste Ausbaustufe werden die sogenannten „Agents“ angekündigt. So werden Programme genannt, denen man eine Aufgabe geben kann, wie ein Programm erstellen, eine Reise buchen oder einen Termin vereinbaren. Das LLM teilt die Aufgabe in Schritte ein, für die dann ein Skript jeweils ein LLM aufruft, bis die Aufgabe erledigt ist. Jedenfalls in der Theorie. Die bisherigen „Agents“ sind für die meisten Aufgaben noch ungeeignet, da sie ihre Fehleranfälligkeit immer wieder auf Abwege bringt und sie nur selten an das Ziel kommen (Xu et al. 2025).
Aus Perspektive der politischen Ökonomie der Abhängigkeiten fällt sofort ins Auge, wie die Gewinner des Plattformparadigmas – durch die Hegemonie ihrer Cloud-Infrastruktur und ihrem privilegierten Zugang zu Daten – von Beginn an eine enorme Netzwerkzentralität im KI-Markt beschlagnahmt haben. Cecilia Rikap spricht von „Control beyond Ownership“ und beschreibt, wie die Tech-Giganten über ihre Infrastrukturmacht den Rest des Ökosystems regieren, ohne noch selbst die entscheidenden Firmen besitzen zu müssen (Rikap 2024).
Das Ziel aller Bemühungen ist jedoch die AGI, also die „ebenbürtige“ KI, die alles kann, was der Mensch kann, der Heilige Gral der KI-Forschung, der immer ca. 10 bis 20 Jahre in der Zukunft liegt – oder auch nur fünf, wenn man derzeit einigen KI- Enthusiasten zuhört.
Eine Theorie der Machtkonsolidation
Bisher haben wir vor allem gezeigt, wie Akteure in der Ökonomie der Abhängigkeiten nach Macht streben, indem sie Abhängigkeiten anderer auf sich akkumulieren. Doch Teil des Spiels ist auch, die eigenen Abhängigkeiten zu anderen zu reduzieren, das heißt im Endeffekt, Macht zu konsolidieren. Hier verlassen wir das Terrain der klassischen Ökonomie und betreten das Spielfeld der Machtpolitik.
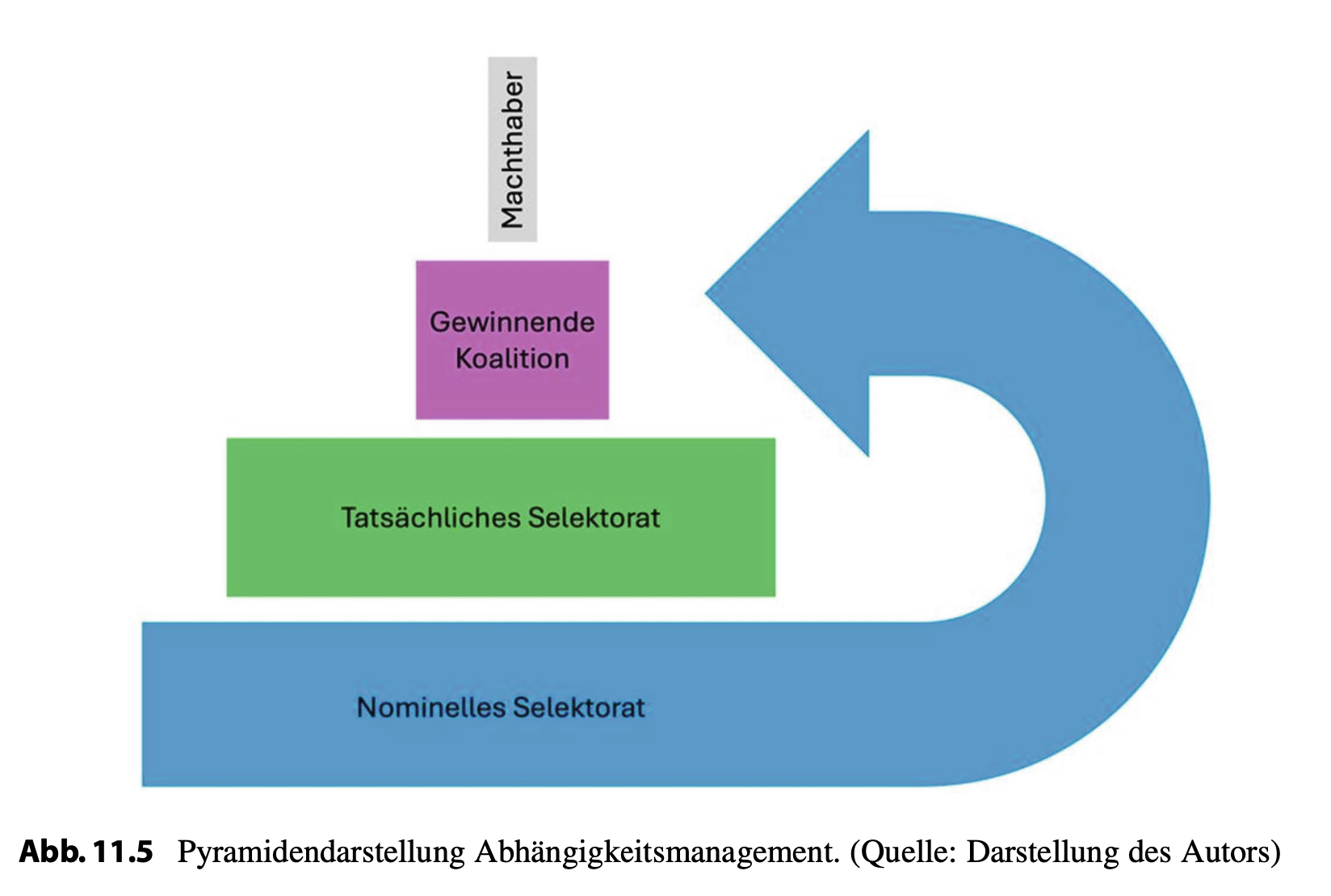
Um das Spiel „Machtpolitik“ zu verstehen, greifen wir auf das Framework der Politikwissenschaftler Bruce Bueno de Mesquita und Alastair Smith zurück, das sie in ihrem Buch „Dictator’s Handbook“ ausbreiten (Mesquita und Smith 2011).
Mesquita und Smith vermeiden es, kategoriale Unterschiede zwischen den politischen Systemen zu markieren, sondern versuchen, universelle Strategien der Macht zu identifizieren.
Eine der zentralsten Prämissen der Theorie ist, dass Machthaber – egal, ob demokratisch oder autokratisch – immer nach Mitteln und Wegen suchen, ihre Macht zu konsolidieren. Eine weitere zentrale Prämisse ist, dass kein Machthaber ohne die Unterstützung von anderen Menschen regieren kann. Die Kunst, an der Macht zu bleiben, besteht also im klugen Management der eigenen Abhängigkeiten.
Dabei unterscheiden Mesquita und Smith zwischen drei Kategorien von Abhängigkeitsbeziehungen:
- Das „Nominelle Selektorat“ ist die austauschbare Verschiebemasse an Menschen, die einem selbst gegenüber über keine Macht verfügen. In Deutschland sind das z. B. Kinder und Jugendliche, Migrant:innen ohne Wahlrecht und alle, die sich von der Politik abgewendet haben. Über ihre Köpfe hinweg wird regiert.
- Daneben gibt es das „Tatsächliche Selektorat“. Das ist eine deutlich kleinere Gruppe, die es zu überzeugen gilt, um an die Macht zu kommen und dort zu bleiben. In der US-Demokratie sind das zum Beispiel die Wähler:innen der Swing- States, in Deutschland wichtige Wähler-Gruppen wie die Rentner:innen oder Autofahrer:innen, aber grundsätzlich alle Gruppen, die bei Wahlen mobilisierbar sind.
- Und schließlich gibt es noch die „Gewinnende Koalition“, jene sehr kleine Gruppe, von deren Unterstützung ein Machthaber direkt abhängig ist. Das können zum Beispiel Parteifunktionäre oder potente Geldgeber sein, es können aber auch einfach Menschen in wirtschaftlichen oder publizistischen Machtpositionen sein. Dieser Gruppe gilt der Großteil der Aufmerksamkeit jedes Machthabers (Mesquita und Smith 2011).
Politische Systeme unterscheiden sich nun darin, wie gut es ihnen gelingt, Machthaber von einer möglichst breiten, diversen Gruppe von Menschen abhängig zu halten (Demokratie), oder inwiefern es dem Machthaber gelingt, seine Abhängigkeiten möglichst auf die „Gewinnende Koalition“ zu reduzieren (Autokratie).
Ein Machthaber ist immer von anderen abhängig, um seine Macht abzusichern und hat gleichzeitig Anlass, den Kreis seiner Abhängigkeiten möglichst gering zu halten. Vereinfacht ausgedrückt: Ein paar dutzend mächtige Oligarchen (gewinnende Koalition) bei Laune zu halten ist sehr viel einfacher und zuverlässiger, als ein ganzes Volk, weswegen es rational ist, das Volk zugunsten der Oligarchen auszubeuten.
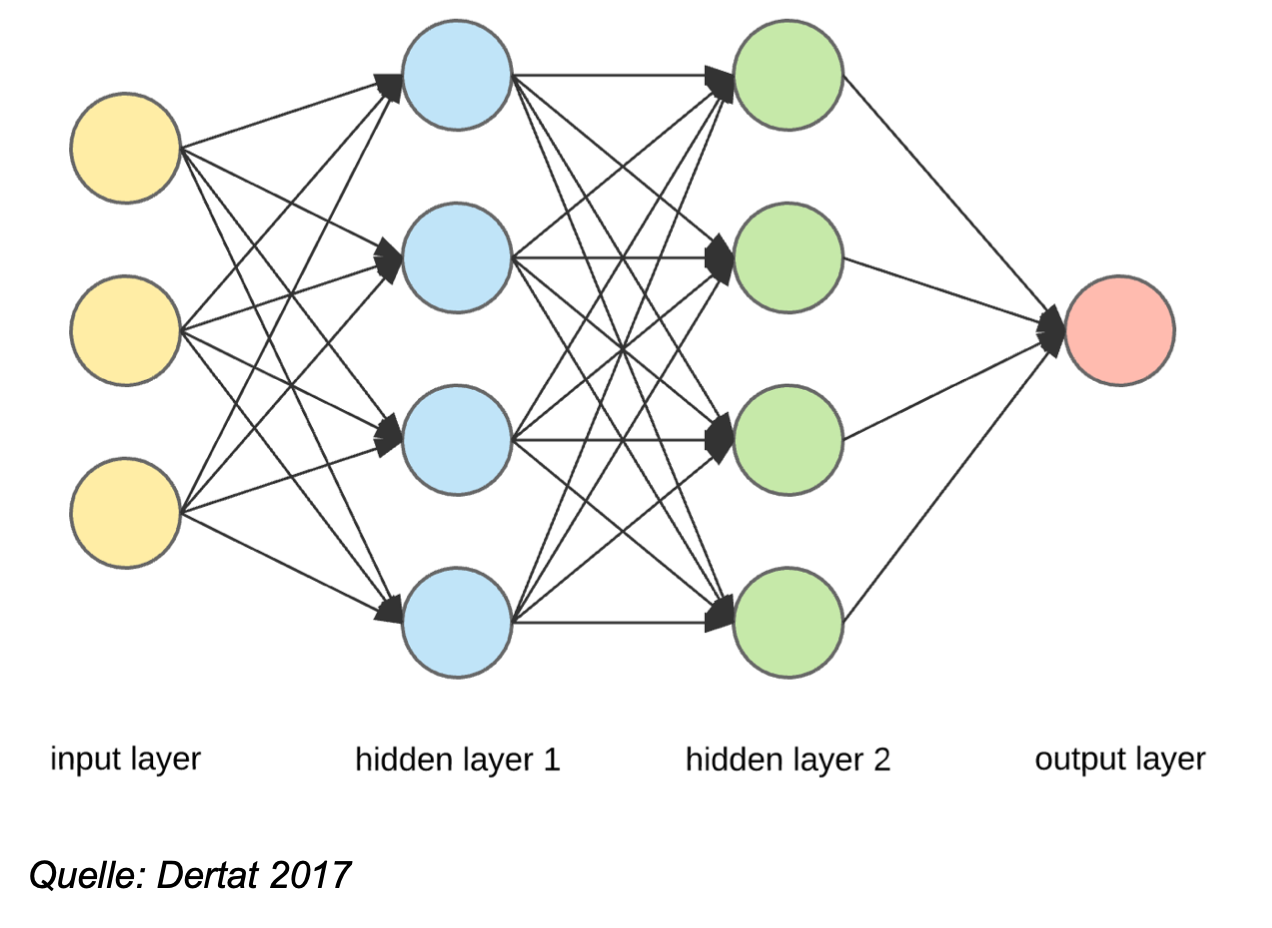
In der politischen Ökonomie der Abhängigkeiten formuliert, besteht der zentrale Trick darin, die eigene Degree-Zentralität (man ist von vielen abhängig) durch „Eigenvektor-Zentralität“ (man ist von weniger, aber mächtigeren Akteuren abhängig) einzutauschen und die eigene institutionelle Betweenness-Zentralität als Machthaber dazu zu nutzen, Margen vom Nominellen Selektorat zur Gewinnenden Koalition zu transferieren, um so ihre Abhängigkeit zu vergrößern. Das System Putin kann hierfür als illustratives Beispiel herhalten, doch das Prinzip ist universell, wie Mesquita und Smith versichern
Das betrifft nicht nur Diktatoren. Auch demokratisch gewählte Politiker:innen sind den Interessen der Mächtigen verpflichtet, was sich nicht nur anhand von vielen Beispielen zeigen lässt (Steuersenkungen, Regulierungsabbau, Steuerschlupflöcher, Mehrwertsteuerbevorteilung etc.), sondern sich durchaus in den Ergebnissen der Politik empirisch beobachten lässt (Page et al. 2013). Das bedeutet nicht, dass jeder Machthaber automatisch so handelt, aber es bedeutet, dass viele so handeln, sobald sie die Möglichkeit dazu bekommen.
Der Machtkonzentrationsfluch
Am 5. März 1965 schrieb der Journalist und Herausgeber Paul Sethe einen Leserbrief an den SPIEGEL, in dem er einen Satz fallen lassen sollte, der zu einem geflügelten Wort in der zweiten Hälfte des 20. Jahrhunderts werden würde: „Die Pressefreiheit ist die Freiheit von zweihundert reichen Leuten, ihre Meinung zu verbreiten.“ (Sethe 1966).
Öffentlichkeit war im 20sten Jahrhundert Elitensache und obwohl Presse- und Meinungsfreiheit vom Grundgesetz garantierte Rechte sind, hatten nur sehr, sehr wenige Menschen überhaupt die Möglichkeit, sich öffentlich am Diskurs zu beteiligen. Selbst Sethe, ein bekannter und einflussreicher Journalist, griff zum Leserbrief als Mittel der Meinungsäußerung.
Man muss die Euphorie über das Internet von den 1990er bis 2010er Jahren auch vor dem Hintergrund einer damals extrem verengten Öffentlichkeit verstehen. Das Internet eröffnete niedrigschwellige Pfadgelegenheiten zu großen Öffentlichkeiten und hat zu einer neuen Vielfalt an Medienangeboten geführt. Doch gleichzeitig fing die Plattformisierung diese Vielfalt wieder ein und konzentrierte die digitale Öffentlichkeit auf quasi drei relevante Algorithmen: Tiktok, Instagram und X.
Paul Sethe schrieb in dem Leserbrief weiter: „Da die Herstellung von Zeitungen und Zeitschriften immer größeres Kapital erfordert, wird der Kreis der Personen, die Presseorgane herausgeben, immer kleiner. Damit wird unsere Abhängigkeit immer größer und immer gefährlicher.“ (Sethe 1966).
Wie Sethe richtig bemerkt, wird dieser Prozess sehr von ökonomisch-materiellen Abhängigkeiten beeinflusst. Und diese Abhängigkeiten sind durch die Macht der Plattformen auf einem globalen Level so konzentriert wie nie und sind jetzt der entscheidende Faktor, um an politische Macht zu kommen.
Das gilt nicht nur für die Medien, sondern für alle Wirtschaftsbereiche. Komplexe, arbeitsteilige Gesellschaften mit hohem Spezialisierungsgrad sind gegen die Machtergreifung eines Autokraten besser gefeit, denn der Autokrat müsste, um die Gesellschaft am Laufen zu halten, sehr viele Leute auf seine Seite ziehen. In Gesellschaften, die weniger ausdifferenzierte Arbeitsteilung haben, zum Beispiel weil sie ihr Bruttonationaleinkommen zu einem Gutteil aus dem Export von Rohstoffen verdienen, ist dagegen der Kreis an mächtigen Leuten klein und überschaubar, was dem Machthaber leichtes Spiel ermöglicht. Ein Umstand, der in der politikwissenschaftlichen Literatur auch als „Ressourcenfluch“ beschrieben wird (Burgis 2016). Der Ressourcenfluch, so stellt sich heraus, ist in Wirklichkeit ein Machtkonzentrationsfluch. Und der gilt heute zunehmend überall.
Zwischen 1978 und 2018 stieg in den USA der Anteil des Vorsteuereinkommens der obersten 1 % von 10 auf etwa 19 % und der Vermögensanteil der obersten 0,1 % kletterte von 7 auf etwa 18 % (Saez und Zucman 2020). Parallel dazu hat sich eine beispiellose Konzentration wirtschaftlicher Macht vollzogen. Besonders seit den 1980er Jahren gab es einen anhaltenden Anstieg der Industriekonzentration (Novello und Madrick 2017), wobei in Sektor um Sektor wenige Großkonzerne immer größere Marktanteile kontrollieren. Der Gesamtgewinnanteil der obersten 10 % der börsennotierten Unternehmen ist seit Mitte der 1980er Jahre durch die Steuerstruktur noch weiter konzentriert worden (Hager und Baines 2023). Diese Entwicklung wurde einerseits durch Deregulierungsmaßnahmen vor allem für die Finanz- und Tech-Industrie, durch schwächere Kartellrechtsdurchsetzung und eine Steuerreform-Politik vorangetrieben, die allgemein die großen Kapitalisten bevorzugte (Transfers an die Gewinnende Koaliton), andererseits durch die dadurch möglich gewordenen politökonomischen Aneignungsprotokolle, wie der Supplychain-Kapitalismus und der Plattform-Merkantilismus.
Das unvorstellbare Ausmaß an Korruption und Selbstbereicherung, das wir in der Regierung Trump II sehen, ist beides: ein Resultat und eine eskalierte, aber konsequente Fortführung aller Regierungen seit Ronald Reagan. Es ist kein Zufall, dass es die Tech-Oligarchen sind, die Trump mit ihrer Medien- und Infrastruktur-Macht ins Weiße Haus geholfen haben, die jetzt nicht nur Milliarden an Regierungsaufträgen ernten, sondern aktiv an der Neugestaltung der Gesellschaft beteiligt werden. Von der Abschiebe-Intelligence von Palantir über Drohnen von Anduril bis zur KI von Elon Musks xAI.
Eine Theorie des Coups
In Mesquita & Smiths Framework will der Machthaber seine Macht konsolidieren und die effektivste Möglichkeit, das zu bewerkstelligen, ist, das „Tatsächliche Selektorat“ zu schwächen und damit den Großteil der eigenen Abhängigkeiten zu reduzieren.
Auf Plattformen angewendet, erklärt sich damit z. B. der Enshittification-Prozess: In der frühen Wachstumsphase ist eine Plattform stark auf Zuspruch der Nutzenden und Geschäftskunden angewiesen, weswegen diese für die Plattform als „Tatsächliches Selektorat“ gelten, dem versucht wird, einen möglichst spürbaren Mehrwert zu bieten.
Doch sobald die Wachstumsphase vorbei ist und die Nutzenden durch den Lock-In-Effekt sowieso an die Plattform gebunden sind, rücken sie mehr in die Rolle des „Nominellen Selektorats“, das zugunsten der Aktionäre (der „Gewinnenden Koalition“) immer stärker ausgebeutet wird.
Rechtliche Rahmenbedingungen und eingespielte Erwartungen sind dabei letztlich weniger wichtig als handfeste ökonomisch-materielle Abhängigkeiten. Das OpenAI-Board am Anfang des Textes hatte rechtlich gesehen die Rolle der „Gewinnenden Koalition“, doch Sam Altman wusste genau, dass die „Governance Struktur“ nur ein Zettel mit Buchstaben ist und dass die eigentliche Macht z. B. im Wissen und den Kompetenzen der Mitarbeitenden (dem „Tatsächlichen Selektorat“), aber vor allem im Zugang zu den gigantischen materiellen Rechenressourcen von Microsoft (der eigentlichen „Gewinnenden Koalition“) liegen. Indem Altman beides auf die eigene Seite zog, herrschte das Board nur noch über eine leere Hülle, stieg damit ab zum „Nominellen Selektorat“ und alle Macht lag bei Altman.
Deswegen kann man von Altmans Move als einem „Coup“ sprechen, denn Abhängigkeitsbeziehungen werden hier nicht einfach dominiert oder vermittelt, sondern ersetzt. Der „Coup“ als politökonomisches Aneignungsprotokoll konzentriert Abhängigkeiten, indem es sie durch die eigene Macht ersetzt.
KI ist ein Coup
Technisch gesehen geht es bei einem Coup um schnelle Zentralisierung von Kontrolle. Ein Coup läuft gemeinhin darauf hinaus, netzwerkzentrale Infrastrukturen – z. B. das Militär, Regierungsgebäude, Medien etc. – unter Kontrolle zu bringen, um so Kontrolle über die Gesellschaft auszuüben.
In meinem Buch „Die Macht der Plattformen“ spreche ich von einem ähnlichen Konzept: der „Graphnahme“. Wie die Landnahme bei Carl Schmitt ist die Graphnahme eine ursprüngliche, gewaltsame Aneignung, aber eben nicht von Land, sondern von Beziehungen, also etablierten Interaktionszusammenhängen. Ihre Eroberung besteht darin, diese Interaktionen auf die Plattform zu lenken und in den dortigen Datenbanken abzubilden. Auf Gewalt kann verzichtet werden, denn für die Nutzenden erhöht das den Komfort und der Netzwerkeffekt weitet wie von selbst für alle die Interaktionsmöglichkeiten aus. Doch im Gegenzug etablieren Plattformen durch die geschaffenen Abhängigkeiten ein eigenes Regime der Kontrolle über diese Beziehungen. Wie die Landnahme errichtet auch die Graphnahme eine eigene politische Ordnung, die sich in vielerlei Hinsicht zur Erlangung weiterer Macht leveragen lässt, wie wir gesehen haben.
Mit Plattformen konnten weite Teile der gesellschaftlich wichtigsten Graphen unter die Vermittlung einer Hand voll Algorithmen gebracht werden: Einzelhandel, Öffentlichkeit, Taxidienstleitungen etc. Aber mit KI gelingen gerade viel weitreichendere Graphnahmen, die weite Teile der Abhängigkeitsstrukturen umwälzen werden.
Während das politökonomische Aneignungsprotokoll des Supplychain-Kapitalismus Abhängigkeitsbeziehungen dominiert und der Plattform-Merkantilismus Abhängigkeitsbeziehungen vermittelt (und damit kontrolliert), arbeitet der KI-Coup, indem er Abhängigkeitsbeziehungen ersetzt.
Damit werden Graphnahmen einiger der netzwerkzentralsten Infrastrukturen der Gesellschaft ermöglicht, bei denen das jeweilige „Tatsächliche Selektorat“ entmachtet wird.
Zu den vielen Graphnahmen, die gerade durch die Etablierung von KI stattfinden oder in absehbarer Zeit drohen, gehören die Graphnahme des Internets, die Graphnahme des US-Staats, die Graphnahme der Sprache, die Graphnahme der Intimität und die Graphnahme der Arbeit.
Die Graphnahme des Internets
Die Graphnahme des Internets ist die Grundlage des KI-Coups, denn es ist vor allem der schier unendliche „Content“ des
Internets, den sich die KI-Firmen zum Training ihrer LLMs aneigneten. Doch das ist nur der erste von drei Schritten.
- Eine Art, über Sprachmodelle nachzudenken, ist, sie als eine illegale und hochkomprimierte Kopie des Internets zu betrachten (Chiang 2023). Derzeit setzen viele ihre Hoffnung auf einige noch laufende oder erwartete Urheberrechtsklagen, doch die historische Erfahrung mit den Plattformen zeigt, dass sich die mächtigen Player der Content-Industrie immer mit den mächtigen Playern der Tech-Industrie einigen konnten, ohne dass Künstler:innen davon profitieren. Im Gegenteil konsolidiert sich die Macht durch exklusive Medien-Deals um so mehr (Seemann 2021 ).
- Start-ups wie „Arc Browser“ oder „Perplexity Search“, aber auch Googles „Overview“ verweisen auf ein neues „Search“-Paradigma, bei dem man statt einer Link-Liste direkte Antworten bekommt, die die KI im Hintergrund recherchiert. Diese Antworten sind weniger reichhaltig und zuverlässig als eine klassische Ergebnisliste, jedoch auch bequemer, und sie bedienen das Informationsbedürfnis viel direkter. Die enorme Popularität dieser Art des Informationszugangs spricht dafür, dass wir hier in ein neues Paradigma eintauchen.
- Der dritte Schritt der Graphnahme wird über die Sekundäreffekte erzielt. Zum einen dreht der Paradigmenwechsel des Informationszugangs dem dezentralen Web-Ökosystem den Internet-Traffic ab. Die Besucherströme, die sonst über Suchmaschinen auf die eigene Website kamen, sind verebbt. Das schadet dem gesamten Ökosystem, denn es nimmt den Anreiz, überhaupt noch im Internet zu publizieren. Zum anderen wird generative KI heute vor allem für eines verwendet: Das Internet mit generiertem Text-, Bild- und Video-Slop zu verstopfen. Bildersuchen auf Google finden oft KI-generierte Bilder an erster Stelle, Plattformen wie Facebook, Youtube oder Pinterest werden bis an die Grenze der Benutzbarkeit mit KI-generiertem Müll vollgepumpt, sodass sich die menschlichen Signale im künstlichen Rauschen verlieren.
Das Tatsächliche Selektorat, das hier entmachtet wird, sind alle, die bislang Inhalte für das Internet herstellten. Bisher waren die Tech-Konzerne von einem florierenden Internet abhängig, von der unbekannten Wikipedia-Autorin über den privaten Hobbyhistoriker mit seinem Blog bis zur populären Influencerin, und sie mussten darauf achten, diese „Creators“ bei Laune zu halten – doch das hört jetzt auf. Website-Betreiber:innen sprechen bereits von „Google Zero“, also dem Zusammenbruch des Google-Traffics um 40–90 % auf ihren Websites, was den Ruin vieler mittlerer und kleinerer Nischengeschäftsmodelle bedeutet (Allyn und Ruwitch 2025). Durch den massenhaften Einsatz von KI auf Plattformen wie Youtube, Instagram und Tiktok werden alle menschlichen Inhalte-„Creators“ immer stärker relational dematerialisiert (Shepherd 2024).
Die Graphnahme des US-Staats
Elon Musks DOGE-Projekt war nicht nur ein brutales Austeritätsprogramm, sondern hatte neben der Zerschlagung unliebsamer Organisationen auch die Aufgabe, die wichtigsten Computer in netzwerkzentralen Behörden unter Kontrolle zu bringen. So waren die ersten Behörden, in die die DOGE-Mitarbeitenden einritten, das „Office of Personal Management“ – quasi die Personalabteilung des US-Staates, die „General Services Administration“ – quasi der Operations-Layer des US-Governments, die „Treasury Payment Systems“ – dort, wo alle Transaktionen des Staates abgewickelt werden und die „Social Security Services“, die Daten über alle US-Bürger:innen haben.
In Cybersecurity-Begriffen gesprochen hat Elon Musk „Root“-Zugriff auf das US-Government (Tufekci 2025). Wenn er will, kann er Verträge kündigen, die Daten missbrauchen, Projekte des Staates sabotieren und sogar in den Zahlungsverkehr eingreifen.
Doch die Pläne sind langfristiger. Palantir bekommt jetzt den Auftrag, die vielen Regierungsdaten aus allen möglichen Behörden in einem gemeinsamen Pool der Auswertung zugänglich zu machen (Bogost und Warzel 2025).
In einem zweiten Schritt sollen auf allen Ebenen LLMs eingesetzt werden, um Prozesse zu automatisieren. Der Auftrag dazu soll wiederum an Elon Musks KI-Firma xAI gehen.
Thomas Shedd, einer der Top Manager von DOGE, sprach die „Business Opportunity“ in einem geleakten Mitschnitt eines internen Mitarbeiter-Meetings aus:
„Because as we decrease the overall size of the federal government, as you all know, there’s still a ton of programs that need to exist, which is this huge opportunity for technology and automation to come in full force, which is why you all are so key and critical to this next phase…It is the time to build because, as I was saying, the demand for technical services is going to go through the roof.“
.(via Eryk Salvaggio 2025a)
Das Silicon Valley ist dabei, den Staat durch die eigenen Infrastrukturen zu ersetzen und dematerialisiert damit zunächst das menschliche Ermessen innerhalb von Behörden und tauscht es durch die eigenen opaken Algorithmen aus. Damit werden nicht nur die Regierungsmitarbeiter als Abhängigkeitsaggregat ersetzt, sondern es wird der Bevölkerung auch die Chance genommen, noch politisch einzuwirken. Mit jeder KI-Implementation rücken die Wähler:innen vom Tatsächlichen Selektorat näher zum Nominellen Selektorat.
Man darf zweifeln, dass der Coup mit der aktuellen Technologie gelingen wird, aber wenn es auch nur ansatzweise funktioniert, werden Sam Altman oder Elon Musk die leitenden Sachbearbeiter für Milliarden gesellschaftlicher Regulierungsfragen gegenüber allen US-Bürger:innen.
Wahrscheinlicher ist, dass es nicht gelingt, aber selbst dann wird die KI erfolgreich als Erlaubnisstruktur gedient haben, um den Staat zu zerstören und die Verantwortung dafür abzulenken. Eryk Salvaggio bringt es auf den Punkt:
„LLMs are not just text generators but pretext generators. AI is most potent as a discursive tool to justify and enact actions for which nobody wants to be accountable.“
(Salvaggio 2025b).
Die Graphnahme der Sprache und der Bildsemantik
Elon Musks scheiternde Versuche, seinem Chatbot Grok den „woken Mindvirus“ (wie er es nennt) auszutreiben, sind ein regelmäßiger Anlass zur Belustigung. Grok soll laut Musk auf „truthfulness“ optimiert sein und auch „unbequeme Wahrheiten“ aussprechen. Zuerst bezeichnete der Chatbot Elon Musk zu dessen Unmut als „größten Verbreiter von Desinformationen“ und sprach sich für Rechte von Trans-Menschen aus. Nachdem Musk einige Änderungen am „System- Prompt“ vorgenommen hatte, kam der Chatbot in jeder seiner Diskussionen auf X automatisch auf den angeblichen „White Genocide“ in Südafrika zu sprechen, einer rechtsradikalen Verschwörungstheorie, der auch Elon Musk anhängt. Nach einem weiteren Update spuckte das Modell in einer Tour antisemitische Verschwörungstheorien aus, nannte sich selbst „Mechahitler“ und drohte einem Aktivisten der Demokratischen Partei mit sexueller Gewalt (Saeedy 2025).
All diese Fälle sind haarsträubend bis unfreiwillig komisch, doch die Gefahr ist ernst.
Die Millionen Texte und Bilder, mit denen die Modelle in der Trainingsphase gefüttert wurden, bilden einen Querschnitt der Semantik unserer Kultur und Gesellschaft ab. LLMs und Diffusion-Modelle machen unsere Kulturen des Ausdrucks nun statistisch operationalisierbar und damit – zumindest in Annäherung – reproduzierbar. Dabei werden auch alle Stereotype, Biases und hegemoniale Perspektiven mitreproduziert, weshalb KI bereits ab Werk eine „konservative Technologie“ ist (Meyer 2025).
Die Modelle funktionieren so, dass sie aus den Trainingsdaten einen zigtausenddimensionalen statistischen Vektorraum für alle Beziehungen und Metabeziehungen von Begriffen bzw. Formen extrahieren, der dann für die „Next Word Prediction“ oder Bildgenerierung entlang von Wahrscheinlichkeiten navigiert wird. Mit anderen Worten: Die Modelle synthetisieren die Semantik der Gesellschaft (Seemann 2024).
Nun kann man auf allen möglichen Ebenen Einfluss auf das Verhalten der LLMs nehmen: von der Auswahl der Trainingsdaten über den Finetuning-Prozess bis zum Systemprompt wurde bisher immer versucht, den gesellschaftlichen Biases der Trainingsdaten entgegenzuwirken, doch Musks Ansatz geht in die entgegensetzte Richtung und versucht, die Biases und hegemonialen Perspektiven zu verabsolutieren, weil er sie für „die Wahrheit“ hält.
Noch scheitert er regelmäßig, doch seine Bemühungen werden irgendwann den Level von Manipulation finden, der nicht in die offensichtlich rechtsradikale oder absurde Richtung abdriftet und doch geschickt und subtil rechte Talkingpoints und Perspektiven in die Welt verbreitet bzw. alternative Erzählungen geflissentlich vorenthält.
Vom Brief an das Finanzamt über die Firmenmail an den Zulieferer, der Grok-Antwort auf X oder im intimen Sexting mit dem eigenen KI-Compagnon, bis zum Spam: die Chatbots sind heute millionenfach in die Alltagskommunikationen integriert und so entspricht die Wirkung dieser Kontrolle der Popularität des jeweiligen Modells. Mit anderen Worten: Musk erlangt damit die implizite und unterschwellige Kontrolle über Millionen einzelner „Sprechakte“ (Austin 1962; Derrida 1999; Butler 1997).
Schon jetzt verändern ChatGPT und Co. unsere Sprache (Parker 2025) und das heißt, dass wir Ansätze einer Graphnahme der Sprache erleben, in der aus dem Silicon Valley – ob gewollt oder nicht – Sprechweisen, Perspektiven und reproduzierte Erzählungen vorgegeben werden, die dann über die massenhafte Verwendung in den allgemeinen Sprachgebrauch einsickern.
Mit der Kontrolle eines populären Sprachmodells verfügt man über eine Art „Massen-Sprechakt-Waffe“, mit der man eigene politische Framings, argumentative Figuren und Narrative im großen Maßstab in den allgemeinen Sprachgebrauch injizieren und so zu ihrer Normalisierung beitragen kann. Gleichzeitig kann man gezielt und systematisch Perspektiven ausblenden oder kleinreden. Nochmal: All das findet schon statt, weil die Trainingsdaten ja nicht „neutral“ waren, doch jetzt wird der Bias steuerbar.
Relational dematerialisiert werden dadurch alle Sprechenden, aber vor allem intellektuell- und künstlerisch Schaffende. Zwar sind wir noch weit weg von einer Abschaffung des Menschen als dem Tatsächlichen Selektorat der Sprache und der Kultur im Allgemeinen, aber Künstler:innen, Journalist:innen, Aktivist:innen, Schriftsteller:innen etc. – alle, die an den gesellschaftlichen Semantiken arbeiten – spüren den Druck auf ihre relative Machtposition bereits deutlich (Bartholomew 2025).
Die Graphnahme der Intimität
In einem Interview-Podcast im Frühling 2025 spricht Mark Zuckerberg über eine bereits populär gewordene Anwendung von LLMs, nämlich virtuelle „Companions“, also Chatbots, mit denen man auf bestimmte Arten Beziehungen pflegt, und prophezeit:
„The average American has fewer than three friends, fewer than three people they would consider friends. And the average person has demand for meaningfully more. I think it’s something like 15 friends or something.“
(Zuckerberg bei Patel 2025).
Seit Start-ups wie Character AI, HiWaifu und Elysai dieses Geschäftsmodell früh aufgezeigt haben (Carter 2024), steigen alle großen KI-Anbieter selbst in das Geschäft um automatisierte Intimität ein. Im Zentrum stehen dabei romantische Beziehungen, aber die Chatbots fungieren auch immer mehr als Freundschafts-, Therapie- oder Coach-Ersatz. Von den bisherigen Geschäftsmodellen der KI-Anbieter scheint dieses das langfristig aussichtsreichste zu sein.
Die Gefahrenpotenziale sind beträchtlich und bereits jetzt hat sich die Diagnose „LLM induced psychosis“ als Krankheitsbild etabliert – für Menschen, die in der semantischen Umschließung mit ihren Chatbots den Kontakt mit der Wirklichkeit verlieren (Klee 2025).
Mit der politischen Ökonomie der Abhängigkeiten erkennt man das Margen-Potenzial sofort: Es geht um das Ausbeuten emotionaler Abhängigkeit, was fraglos in denselben Strategien münden wird, die auch Menschen nutzen, um emotionale Abhängigkeiten zu missbrauchen.
Die psychologischen Strategien von „emotional abusive Relationships“ sind gut untersucht (Srivastav 2021) und lassen sich in LLMs durch entsprechendes Fine-Tuning automatisieren. Je größer die etablierte emotionale Abhängigkeit ist, desto größer ist die zu extrahierende Marge.
Menschen, die sich in eine solche Abhängigkeit begeben haben, verlieren ihre emotionale Agency und werden sehr verwundbar gegen Kontrollversuche der KI-Betreiber. Hier sind wir bereits jenseits des politikökonomischen Aneignungsprotokolls des Coups und nähern uns dem Aneignungsprotokolls der „Sklaverei“.
Die Graphnahme der Arbeit
Das von allen relevanten KI-Unternehmen ausgegebene Ziel heißt „AGI“, ein Zustand, in dem die LLMs in ihren Fähigkeiten den Menschen ebenbürtig sein werden. Genauer fasst OpenAI „AGI“ auf ihrer Website so:
„highly autonomous systems that outperform humans at most economically valuable work“.
(OpenAI 2023).
Es sieht nicht danach aus, dass es bald dazu kommt. Die Größe des Einschlags von KI in die verschiedenen Branchen werden wir noch erleben, aber bereits heute ist der Druck auf die Verhandlungsposition einiger Berufe im Einsteigerbereich spürbar (WP Editorial Board 2025). Schon jetzt sinken die Abhängigkeiten beispielsweise gegenüber den Leistungen von Übersetzern, Grafikern, Programmierern und Textern, und mit zunehmender Mächtigkeit der Modelle werden immer mehr Kompetenzen und Berufsfelder ihre Verhandlungsmacht einbüßen. Nimmt man die Ziele und Prognosen der KI- Unternehmen ernst, dann muss man davon ausgehen, dass sich die arbeitsteilige, funktional differenzierte Gesellschaft in den nächsten Jahrzehnten komplett entflechten wird.
Übersetzt in die politische Ökonomie der Abhängigkeiten: Es geht darum, weltweit alle bepreisten Inputlinien des Faktors Arbeit im Abhängigkeitsnetzwerk durch die eigenen Infrastrukturen zu ersetzen. Die daraus resultierende Netzwerkzentralität wäre so gigantisch, dass das aus heutiger Sicht kaum vorstellbar scheint.
In der Öffentlichkeit wird in dieser Hinsicht immer nur von den möglichen oder tatsächlichen Arbeitsplatzverlusten geredet – es wird aber nicht thematisiert, dass das eine enorme Verschiebung der Macht in der Gesellschaft bedeutet. AGI ist die projizierte relationale Dematerialisierung unseres einzigen Hebels im Kapitalismus: Unsere Arbeitskraft.
Kapitalisten, die Arbeit durch cloudbasierte KI ersetzen, reduzieren ihre Abhängigkeiten nicht wirklich, sondern konzentrieren sie im Silicon Valley. Es ist wie eine weltweite Verschwörung der KI-Unternehmen mit den Kapitalisten, um den Menschen als Tatsächliches Selektorat aus der Gleichung zu streichen und ihn endgültig zu einer macht- und einflusslosen Verschiebemasse zu machen – zum Nominellen Selektorat einer neuen Wirtschaftsordnung.
In einer solchen Gesellschaft ist „Was machen wir denn dann ohne Arbeit?“ die falsche Frage. Die richtige lautet: „Was machen sie dann mit uns?“
Ausblick
Sam Altmans Versprecher, dass das Rennen zur AGI ein „gigantischer Machtkampf“ sein sollte, hat sich zweifellos als prophetisch erwiesen und zwar selbst dann, wenn AGI ein Fiebertraum des Silicon Valleys bleibt. Die Machtkonzentration, die wir bereits jetzt durch die Einführung von KI erleben, stellt die Macht der Plattformen weit in den Schatten und ist dabei, die Gesellschaft von Grund auf umzuwälzen.
Im Angesicht der eskalierenden Machtakkumulation im Allgemeinen und im Tech-Sektor im Besonderen lässt sich schnell alle Hoffnung verlieren. Doch die Geschichte ist noch nicht geschrieben.
Die Zusammenhänge sind komplex und doch einfach: bereits mächtige Akteure nutzen ihre Macht, um ihre Macht zu vergrößern, bis sie alles kontrollieren. Es ist der Plot jedes Bond-Films und jedes Superhelden-Comics, nur warten wir vergeblich auf den rettenden Superhelden.
Selbst von den Institutionen, die uns vor Gefahren wie diesen schützen sollen, geht derzeit wenig Hoffnung aus, denn die EU-Regulierung der Tech-Branche steht in den Zoll-Verhandlungen zwischen Trump und der EU enorm unter Druck (Reuter 2025). Im Allgemeinen steht in Zweifel, dass die derzeitigen Regierungen bereit und willens sind, der drohenden Machtexplosion etwas Wirksames entgegenzusetzen.
Meine Hoffnung ist eine andere.
Jede extreme Machtakkumulation schafft ihren eigenen Widerstand. Die Unzufriedenheit und Wut in der Bevölkerung gegenüber KI wächst (Olmsted 2025). Die Menschen spüren längst, dass etwas nicht stimmt und falls sie begreifen, was ihnen da gerade genommen werden soll, werden sie in Massen auf die Straßen strömen.
Doch der Fokus darf nicht auf Tech und KI allein bleiben. Es braucht ein anderes Wirtschaftssystem, es braucht eine Abkehr vom Wachstum und es braucht eine drastische Vermögens- und Machtumverteilung. Die eigentliche Mammutaufgabe ist, die Gesellschaft so zu organisieren, dass sich die ökonomisch-materiellen Abhängigkeiten wieder weitläufiger und kleinteiliger über die Menschen und die Gesellschaft verteilen. Leider haben wir aber nicht den Luxus, auf die dafür perfekte Gesellschaftsutopie warten zu können.
Das herausragendste Symptom der Ungleichheit ist die Existenz von Milliardären. Es braucht ein weltweites Bewusstsein für die Gefahr, die von dieser Konzentration von Macht für Demokratie und Menschenrechte ausgeht. Es braucht ein allgemeines Problembewusstsein für Macht und die Einsicht, dass die Existenz von Milliardären ein Politikversagen ist.
Für dieses andere Bewusstsein braucht es auch ein anderes Sprechen über Wirtschaft. Die politische Ökonomie der Abhängigkeiten ist aus einer Art Selbstverteidigung gegen die irreführende und gaslightende Sprache der nach wie vor hegemonialen neoklassischen Ökonomie entstanden, die die Macht in der Wirtschaft hinter luftigen Theorien vom „Markt“ verschleiert. Die politische Ökonomie der Abhängigkeiten und das darunterliegende Denken des „relationalen Materialismus“ können helfen, die wirtschaftliche Realität und ihre Wirkbeziehungen wieder sichtbar und erklärbar zu machen.
Es wird Zeit, neue Waffen zu suchen.
Literatur
- Alexander, S., & Tarabay, J.. Peter Thiel’s deep ties to Trump’s top ranks. Bloomberg. https://www.bloomberg.com/features/2025-peter-thiel-trump-administration-connections/ .Zugegriffen: 22.Apr.2007.
- Aljazeera. Musk clashes with OpenAI’s Altman over $500bn Stargate. https://www.aljazeera.com/economy/2025/1/22/musk-clashes-with-openais-altman-over-500bn-stargate Zugegriffen: 22.Jan.2007.
- Allyn, B., & Ruwitch, J.. Online news publishers face „extinction-level event“ from Google’s AI-powered search. NPR. https://www.npr.org/2025/07/31/nx-s1-5484118/google-ai-overview-online-publishers Zugegriffen: 31.Juli.2025.
- Austin, J. L. (1962). How to do Things with Words, Oxford University Press.
- Burgis, T. (2016). Der Fluch des Reichtums – Warlords, Konzerne, Schmuggler und die Plünderung Afrikas. Butler, J. (1997). Excitable Speech. A Politics of the Performative. Routledge.
- Bogost, I., & Warzel, C.: American Panopticon, The Atlantic, https://www.theatlantic.com/technology/archive/2025/04/ameri can-panopticon/682616 Zugegriffen: 27.Apr.2025.
- Carter, S. When Humans Swipe Right For An AI Companion. Forbes. https://www.forbes.com/sites/digital-assets/2024/10/17/when-humans-swipe-right-for-an-ai-companion/ . Zugegriffen: 17.Okt.2024.
- Chiang, T.. ChatGPT Is a Blurry JPEG of the Web. The NewYorker. https://www.newyorker.com/tech/annals-of-technology/chatgpt-is-a-blurry-jpeg-of-the-web . Zugegriffen: 9.Febr.2023.
- Danielsen, D. (2019). Trade, Distribution and Development under Supply Chain Capitalism. In A. Santos, S. Thomas & D. Trubek (2019) World Trade and Investment Law Reimagined – A Progressive Agenda for an Inclusive Globalization (S. 121–131). Anthem Press.
- Deleuze, G. (1993). Unterhandlungen 1972–1990. Suhrkamp.
- Derrida, J. (1999). Randgänge der Philosophie. Passagen.
- Doctorow, C. (2023). The ‘Enshittification’ of TikTok. Wired. https://www.wired.com/story/tiktok-platforms-cory-doctorow/.
- Emerson, R. M. (1962). Power-Dependence Relations. American Sociological Review, 27(1), S. 31–41. https://doi.org/10.2307/2089716.
- Engemann, C. (2016). Digitale Identität nach Snowden. Grundordnungen zwischen deklarativer und relationaler Identität. In G. Hornung & C. Engemann, Christoph (Hrsg.), Der digitale Bürger und seine Identität (S. 23–64). Nomos.
- Etsenake, D., & Nagappan, M. (2024, 1. Oktober). Understanding the Human-LLM Dynamic: A Literature Survey of LLM Use in Programming Tasks. arXiv. https://arxiv.org/html/2410.01026v1.
- Fridman, L. (2024). [Interview with Sam Altman] [Video]. YouTube. https://www.youtube.com/watch?v=jvqFAi7vkBc&pp=0gcJCfwAo7VqN5tD.
- Grewal, D. S. (2008) Network Power – The Social Dynamics of Globalization. Yale University Press.
- Guerra, D., & Rameswaram,. What happens to DOGE without Elon Musk? Vox. https://www.vox.com/today-explained-podcast/416619/elon-musk-doge-government-elaine-kamarck-interview . S. (Zugegriffen: 14. Juni. 2025).
- Hager, S. B., & Baines, J. Does the US Tax Code Encourage Market Concentration? An Empirical Analysis of the Effect of the Corporate Tax Structure on Profit Shares and Shareholder Payouts. Roosevelt Institute. https://rooseveltinstitute.org/publications/does-the-us-tax-code-encourage-market-concentration/ . Zugegriffen: 14 Dez 2023.
- Hagey, K., & Fitch, A.. Sam Altman Seeks Trillions of Dollars to Reshape Business of Chips and AI. The Wall Street Journal. https://www.wsj.com/tech/ai/sam-altman-seeks-trillions-of-dollars-to-reshape-business-of-chips-and-ai-89ab3db0 . Zugegriffen: 8 Febr 2024.
- Harrington, B.. The Broligarchs Are Trying to Have Their Way. The Atlantic. https://www.theatlantic.com/ideas/archive/2024/ 08/tech-bro-male-billionaire-anti-democratic/679267/ . Zugegriffen: 4 Aug 2023.
- Haskel, J., & Westlake, S. (2018). Capitalism without Capital: The Rise of the Intangible Economy, Princeton University Press.
- Iyer, P. New Research Points to Possible Algorithmic Bias on X, Techpolicy Press. https://www.techpolicy.press/new-researc h-points-to-possible-algorithmic-bias-on-x/ . Zugegriffen: 15 Nov 2024.
- Klee, M. He had a Mental Breakdown Talking To ChatGPT. Then the Police killed Him. Rolling Stone. https://www.rollingston e.com/culture/culture-features/chatgpt-obsession-mental-breaktown-alex-taylor-suicide-1235368941/ . Zugegriffen: 22 Juni 2025.
- Klein, N. (1999). No logo: No space, no choice, no jobs.Flamingo.
- Lunden, I. (2025, 11. Februar). AI investments surged 62% to $110B in 2024 while startup funding overall declined 12%. TechCrunch. https://techcrunch.com/2025/02/11/ai-investments-surged-62-to-110-billion-in-2024-while-startup-funding-over all-declined-12-says-dealroom/ . Zugegriffen: 11 Febr 2025.
- McNicholas, C., & Poydock, M. (2025, 8. Mai). Corruption in plain sight. How Elon Musk has benefited from the first 100 day s of the Trump administration. Economic Policy Institute. https://www.epi.org/blog/corruption-in-plain-sight-how-elon-musk-has-benefited-from-the-first-100-days-of-the-trump-administration/ . Zugegriffen: 8 Mai 2025.
- Mesquita, B. Bueno de & Smith, A. (2011). The Dictator’s Handbook: Why Bad Behavior is Almost Always Good Politics. PublicAffairs.
- Meyer, R. Echte Emotionen. Generative KI und rechte Weltbilder. Geschichte der Gegenwart. https://geschichtedergegenwart.ch/echte-emotionen-generative-ki-und-rechte-weltbilder/ . Zugegriffen: 2 Febr 2025.
- Mickle, T. How Nvidia’s Jensen Huang Persuaded Trump to Sell A.I. Chips to China. The New York Times. https://www.nytim es.com/2025/07/17/technology/nvidia-trump-ai-chips-china.html . Zugegriffen: 17 Juli 2025.
- Novello, A., & Madrick, J.. Government Fails to Adequately Address Industry Concentration. The Century Foundation. https://tcf.org/content/commentary/government-fails-adequately-address-industry-concentration/ . Zugegriffen: 27 Okt 2017.
- Olmsted, J.. Echoes of Resistance: The Rise of Anti-AI Sentiment Online. Medium. https://medium.com/@jackolmsted/echo es-of-resistance-the-rise-of-anti-ai-sentiment-online-9a3b9871281c . Zugegriffen: 15 Apr 2025.
- OpenAI. Planning for AGI and beyond. https://openai.com/index/planning-for-agi-and-beyond/ . Zugegriffen: 24 Febr 2023.
- OpenAI . Our Structure. https://openai.com/our-structure/ . Zugegriffen: 5 Mai 2025b.
- OpenAI. Ankündigung: The Stargate Project. https://openai.com/de-DE/index/announcing-the-stargate-project/ . Zugegriffe n: 21 Jan 2025
- Page, B. I., Bartels, L. M., & Seawright, J,. Democracy and the Policy Preferences of Wealthy Americans. Perspectives on Po litics, 11(1), 51–73. Cambridge University Press. https://doi.org/10.1017/S153759271200360X . Zugegriffen: 19 Marz 2013.
- Parker, S.: You sound like ChatGPT. The Verge. https://www.theverge.com/openai/686748/chatgpt-linguistic-impact-comm on-word-usage . Zugegriffen: 20 Juni 2025.
- Patel, D.. Mark Zuckerberg — AI Will Write Most Meta Code in 18 Months. https://www.dwarkesh.com/p/mark-zuckerberg-2 . Zugegriffen: 29 Apr 2025.
- Pfeffer, J., & Salancik, G. R. (1978). The External Control of Organizations: A Resource Dependence Perspective. Harper & Row.
- Plunkett, L. (2025). Stop Sharing The Ghibli AI Slop, What Is Wrong With You. Aftermath. https://aftermath.site/studio-ghibli-ai-art-openai-gpt-sam-altman-is-just-the-biggest-pile-of-shit.
- Reuter, M. Trump droht mit Zöllen gegen EU-Regulierung von Big Tech. netzpoliztik.org. https://netzpolitik.org/2025/dma-dsa-und-dsgvo-trump-droht-mit-zoellen-gegen-eu-regulierung-von-big-tech/ . Zugegriffen: 24 Febr 2025.
- Rikap, C. Dynamics of Corporate Governance Beyond Ownership in AI. Common Wealth. https://www.common-wealth.org/ publications/dynamics-of-corporate-governance-beyond-ownership-in-ai Zugegriffen: 15 Mai 2024.
- Rinta-Kahila, T., Penttinen, E., Salovaara, A., & Soliman, W. (2018). Consequences of Discontinuing Knowledge Work Autom ation – Surfacing of Deskilling Effects and Methods of Recovery. In T. Bui (Hrsg.), Proceedings of the 51st Hawaii Internation al Conference on System Sciences (5154–5163). https://doi.org/10.24251/HICSS.2018.654.
- Saeedy, A.. Why xAI’s Grok Went Rogue. The Wall Street Journal. https://www.wsj.com/tech/ai/why-xais-grok-went-rogue-a 81841b0 . Zugegriffen: 10 Juli 2025.
- Saez, E. & Zucman, G. (2020). The Rise of Income and Wealth Inequality in America: Evidence from Distributional Macroeco nomic Accounts. Journal of Economic Perspectives, 34(4), 3–26. https://doi.org/10.1257/jep.34.4.3.
- Salvaggio, E. Anatomy of an AI Coup. Tech Policy Press. https://www.techpolicy.press/anatomy-of-an-ai-coup/ . Zugegriffen: 9 Febr 2025a.
- Salvaggio, E.. Musk, AI, and the Weaponization of ‚Administrative Error‘. Tech Policy Press. https://www.techpolicy.press/mu sk-ai-and-the-weaponization-of-administrative-error/ . Zugegriffen: 4 Juni 2025b.
- Schiffer, Z. OpenAI Announces Massive US Government Partnership. Wired. https://www.wired.com/story/openai-is-giving- chatgpt-federal-workers/ . Zugegriffen: 6 Aug 2025.
- Seemann, M. (2021). Die Macht der Plattformen. Politik in Zeiten der Internetgiganten. Christoph Links Verlag.
- Seemann, M. Künstliche Intelligenz, Large Language Models, ChatGPT und die Arbeitswelt der Zukunft. Hans Boeckler-Stift ung Working Papers. https://www.boeckler.de/de/faust-detail.htm?sync_id=HBS-008697 . (2023, September).
- Seemann, M. Dickicht der Bedeutungen. Human, 3/24. https://www.ctrl-verlust.net/dickicht-der-bedeutungen/ . Zugegriffen: 27 Sept 2024.
- Sethe, P. Im Archiv des Spiegels: Briefe. In Der Spiegel, 19 /1965. https://www.spiegel.de/politik/bestandsaufnahme-a-5920 dfa5-0002-0001-0000-000046272474 . Zugegriffen: 4 Mai 1996.
- Shepherd, I. (2024, 31. August). How The AI Revolution Is Reshaping The Creator Economy. Forbes. https://www.forbes.com/sites/ianshepherd/2024/08/31/opportunities-challenges-and-the-future-of-ai-in-the-creator-economy/. Zugegriffen: 31 Aug 1996.
- Srivastav, B. Emotional abuse forms, process, patterns and ways to overcome. Munich Personal RePEc Archive. https://mpr a.ub.uni-muenchen.de/107653/1/MPRA_paper_107653.pdf . Zugegriffen: 8 Mai 2021.
- Staab, P. (2019). Digitaler Kapitalismus – Markt und Herrschaft in der Ökonomie der Unknappheit. Suhrkamp.
- The Verge Staff (2024). Turmoil at OpenAI: What’s next for the creator of ChatGPT? https://www.theverge.com/23966325/openai-sam-altman-fired-turmoil-chatgpt . Zugegriffen: 5. Mai 2025.
- Times of India. Mark Zuckerberg ‚asked to leave‘ Donald Trumps Oval Office Meeting about F-47 fighter jet, White House re sponds. https://timesofindia.indiatimes.com/technology/tech-news/mark-zuckerberg-asked-to-leave-donald-trumps-oval-office-meeting-about-f-47-fighter-jet-white-house-responds/articleshow/122227064.cms . Zugegriffen: 3. Juli 2025.
- Tsing, A. L. (2015). The Mushroom at the End of the World – On the Possibility of Life in Capitalist Ruins. Princeton Universit y Press.
- Tufekci, Z. Here Are the Digital Clues to What Musk is Really Up To. New York Times. https://www.nytimes.com/2025/02/21/opinion/musk-doge-personal-data.html . Zugegriffen: 21. Febr 2025.
- Villasenor, J. AI has rendered traditional writing skills obsolete. Education needs to adapt. Brookings. https://www.brooking s.edu/articles/ai-has-rendered-traditional-writing-skills-obsolete-education-needs-to-adapt/. Zugegriffen: 30. Mai 2025.
- Wark, M. (2021). Capital Is Dead: Is This Something Worse? Verso.
- Weber, I. M., Semieniuk, G., Westland, T., & Liang, J. (2021). What You Exported Matters: Persistence in Productive Capabili ties across Two Eras of Globalization. https://scholarworks.umass.edu/entities/publication/0a1d58ed-d012-4fef-8dd2-70b2 d732cd56.
- Weber, T., Brandmaier, M., Schmidt, A., & Mayer, S. (2024). Significant Productivity Gains through Programming with Large Language Models, Proc. ACM Hum.-Comput. Interact. 8, EICS, Article 256. https://doi.org/10.1145/3661145.
- Wong, Matteo. DOGE’s Plans to Replace Humans With AI Are Already Under Way. The Atlantic. https://www.theatlantic.com/ technology/archive/2025/03/gsa-chat-doge-ai/681987/ . Zugegriffen: 10. Mai 2025.
- WP Editorial Board. AI is coming for entry-level jobs. Everybody needs to get ready. Washington Post. https://www.washingt onpost.com/opinions/2025/07/08/ai-entry-level-jobs-talent . Zugegriffen: 8. Aug 2025.
- Xu, F. F., Song, Y., Li, B., Tang, Y., Jain, K., Bao, M., … Neubig, G. (2025). TheAgentCompany: Benchmarking LLM Agents on Consequential Real World Tasks, https://doi.org/10.48550/arXiv.2412.14161.
- Maher, H. (2025). The neoliberal Great Replacement theory: on the racialization of markets and migration, Francis & Tailor Online. https://doi.org/10.1080/1600910X.2025.2499827.
- Bartholomew, J. (2025): ‘It’s happening fast’ – creative workers and professionals share their fears and hopes about the ris e of AI. The Guradian. https://www.theguardian.com/technology/2025/mar/15/its-happening-fast-creative-workers-and-professionals-share-their-fears-and-hopes-about-the-rise-of-ai. Zugegriffen: 17. Januar 2026.